
DeepSeek V3: A New Contender in AI-Powered Data Science
How DeepSeek’s budget-friendly AI model stacks up against ChatGPT, Claude, and Gemini in SQL, EDA, and machine learning
Nvidia stock price slumped over 15% on Monday, Jan 27th, after a Chinese startup DeepSeek released its new AI model. The model performance is on par with ChatGPT, Llama, and Claude but at a fraction of the cost. According to Wired, OpenAI spent more than USD$100m to train GPT-4. But DeepSeek’s V3 model was trained for just $5.6m. This cost efficiency is also reflected in the API costs – for every 1M tokens, the deepseek-chat model (V3) costs $0.14, and the deepseek-reasoner model (R1) costs only $0.55 (DeepSeek API Pricing). Meanwhile, gpt-4o API costs $2.50 / 1M input tokens, and o1 API costs $15.00 / 1M input tokens (OpenAI API Pricing).
Always intrigued by emerging LLMs and their application in data science, I decided to put DeepSeek to the test. My goal was to see how well its chatbot (V3) model could assist or even replace data scientists in their daily tasks. I used the same criteria from my previous article series, where I evaluated the performance of ChatGPT 4o vs. Claude 3.5 Sonnet vs. Gemini Advanced on SQL queries, Exploratory Data Analysis (EDA), and Machine Learning (ML).
I. First Impressions
Here are some quick observations from my initial exploration of DeepSeek’s web chatbot UI:
- Interface: The chatbot UI seems pretty similar to ChatGPT, with all the past chats listed on the left and the current conversation in the main panel.
- Chat Labels: ChatGPT usually labels your past chats with a brief summary. However, by default, DeepSeek labels old chats with the first several words of your prompt. For new chats in the same web session, it simply shows ‘New chat’, which could be confusing when there are multiple. But of course, you can rename any chats for clarity.
- Model Options: In the message input box, you can opt to use the reasoning model (R1) or enable the web search functionality.
- Formatting: The chatbot formats keywords and code snippets neatly, making it easy to read.
II. SQL
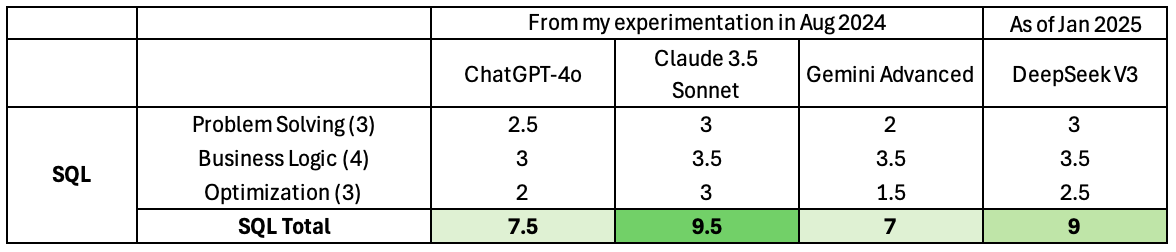
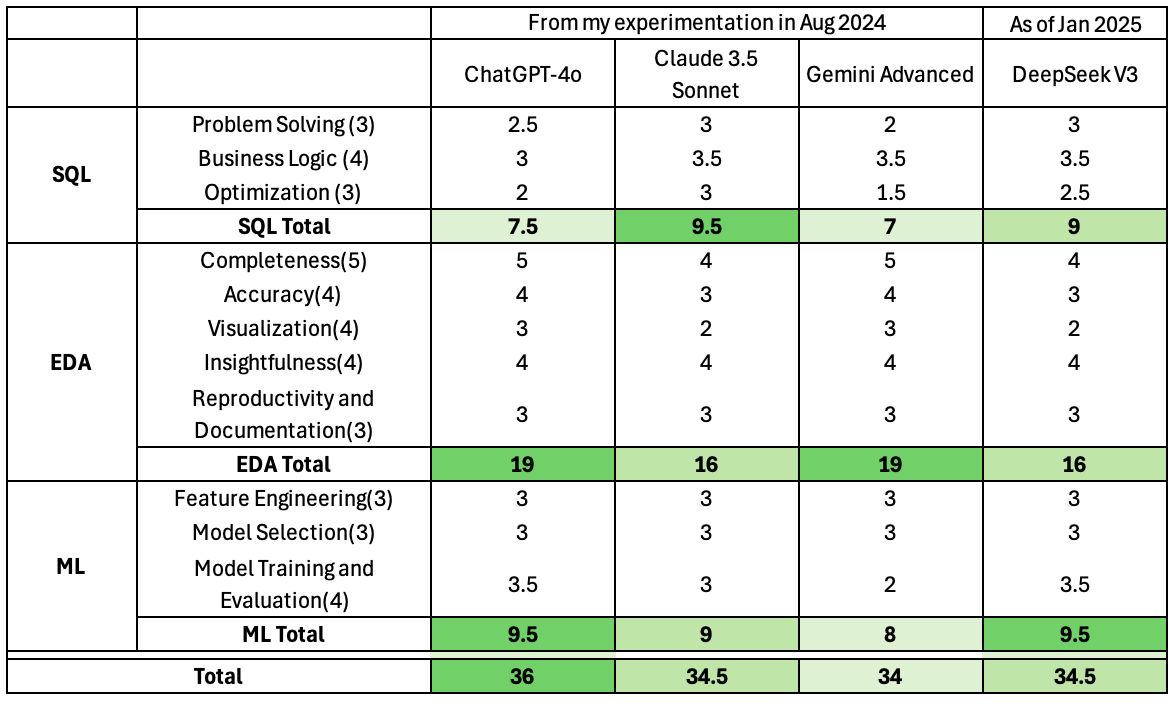
1. Problem Solving (3/3)
I started by testing DeepSeek’s problem-solving skills with three challenging LeetCode SQL questions (262, 185, and 1341) that have low acceptance rates. These questions have clear question descriptions with input and output table structures and are similar to interview questions. DeepSeek aced all three questions using aggregation, filters, window functions, etc. It also offered step-by-step breakdowns and clear explanations.
2. Business Logic (3.5/4)
Next, I uploaded four synthetic datasets to simulate real-world scenarios where table descriptions are often incomplete and you have to assume information based on how the data looks like.
Though the total size of the four CSV files is only ~300KB, I got the error message “DeepSeek can only read 40% of all files. Try replacing the attached files with smaller excerpts.” So I cut the file size down to only 30KB by truncating to the top 100 rows of each file – I no longer got the above error message, but this time it said “Oops! DeepSeek is experiencing high traffic at the moment. Please check back in a little while.” Eventually, I turned to upload screenshots of the top rows of each dataset, which worked.
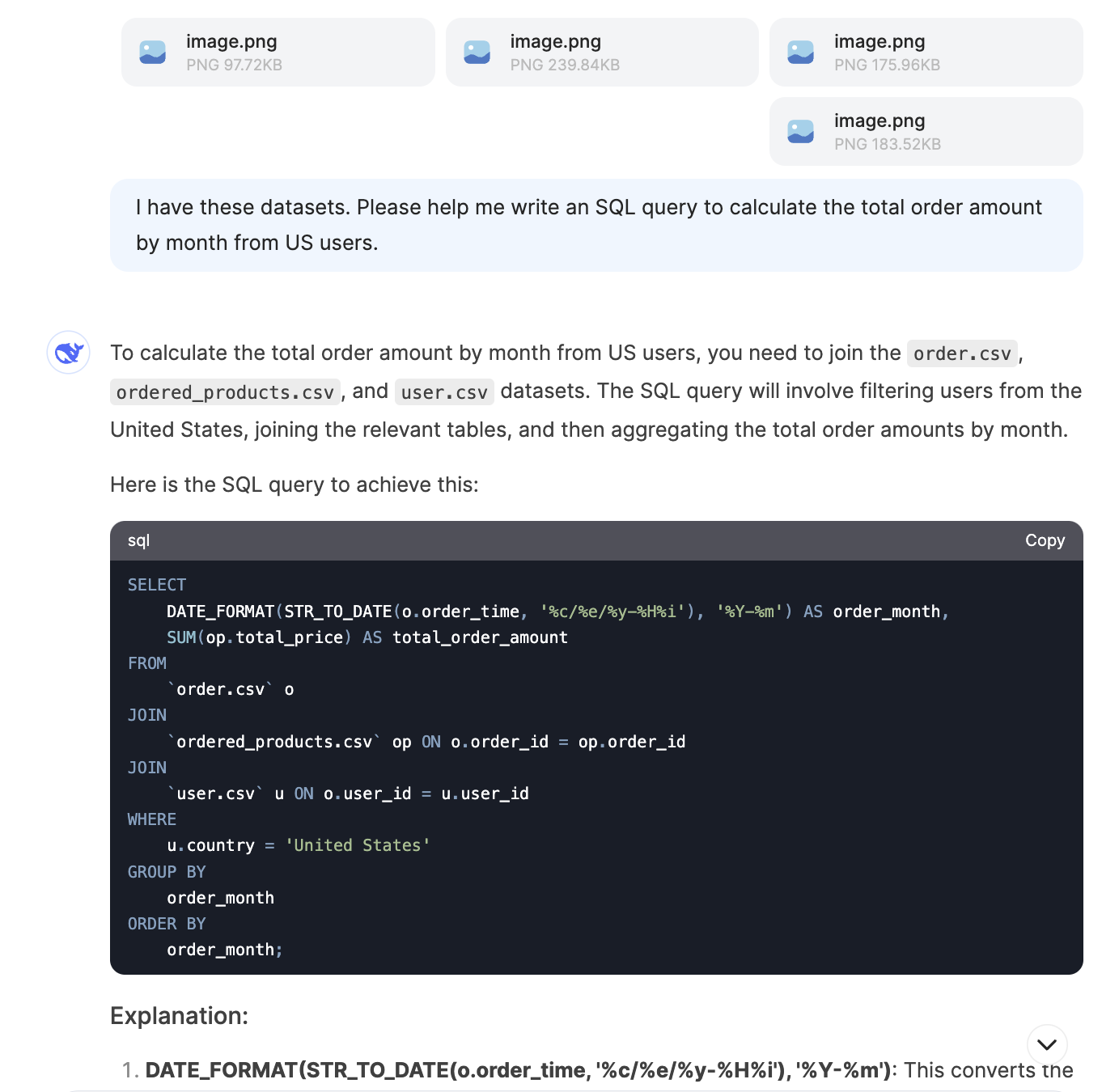
The datasets include:
- users: User-level data with demographic information.
- products: Product-level data.
- orders: Order-level data with payment information.
- ordered_products: A table linking orders and products.
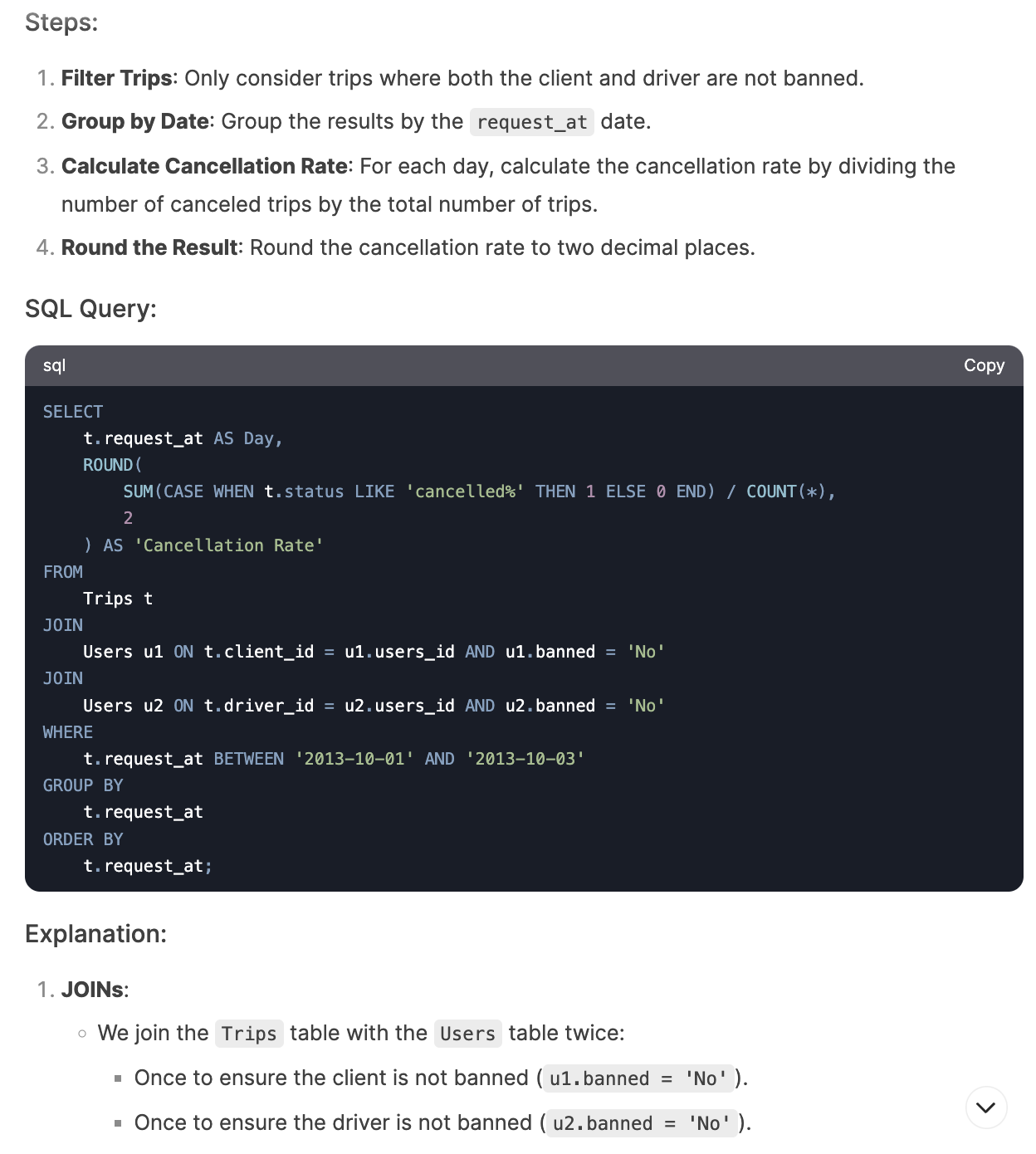
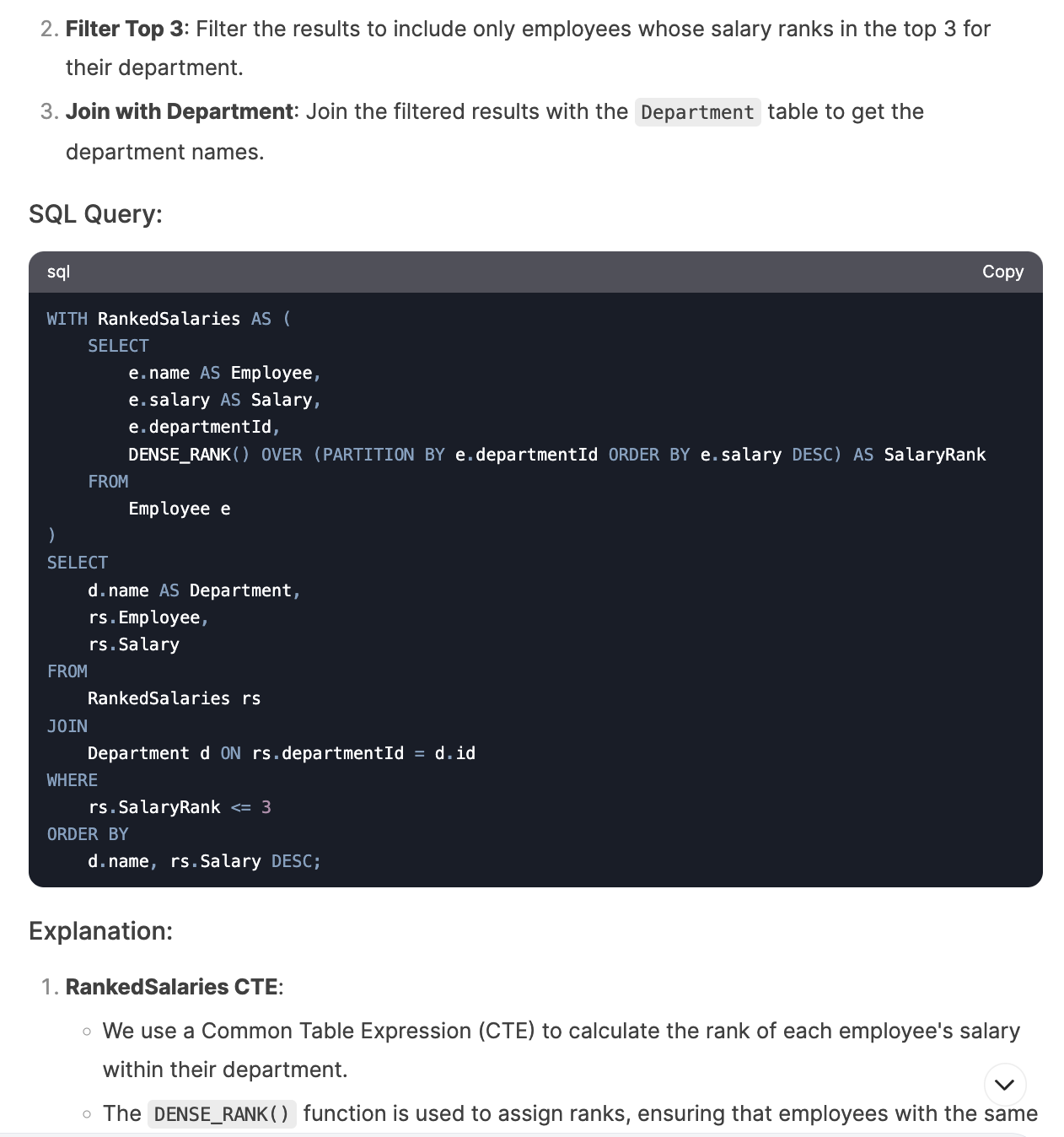
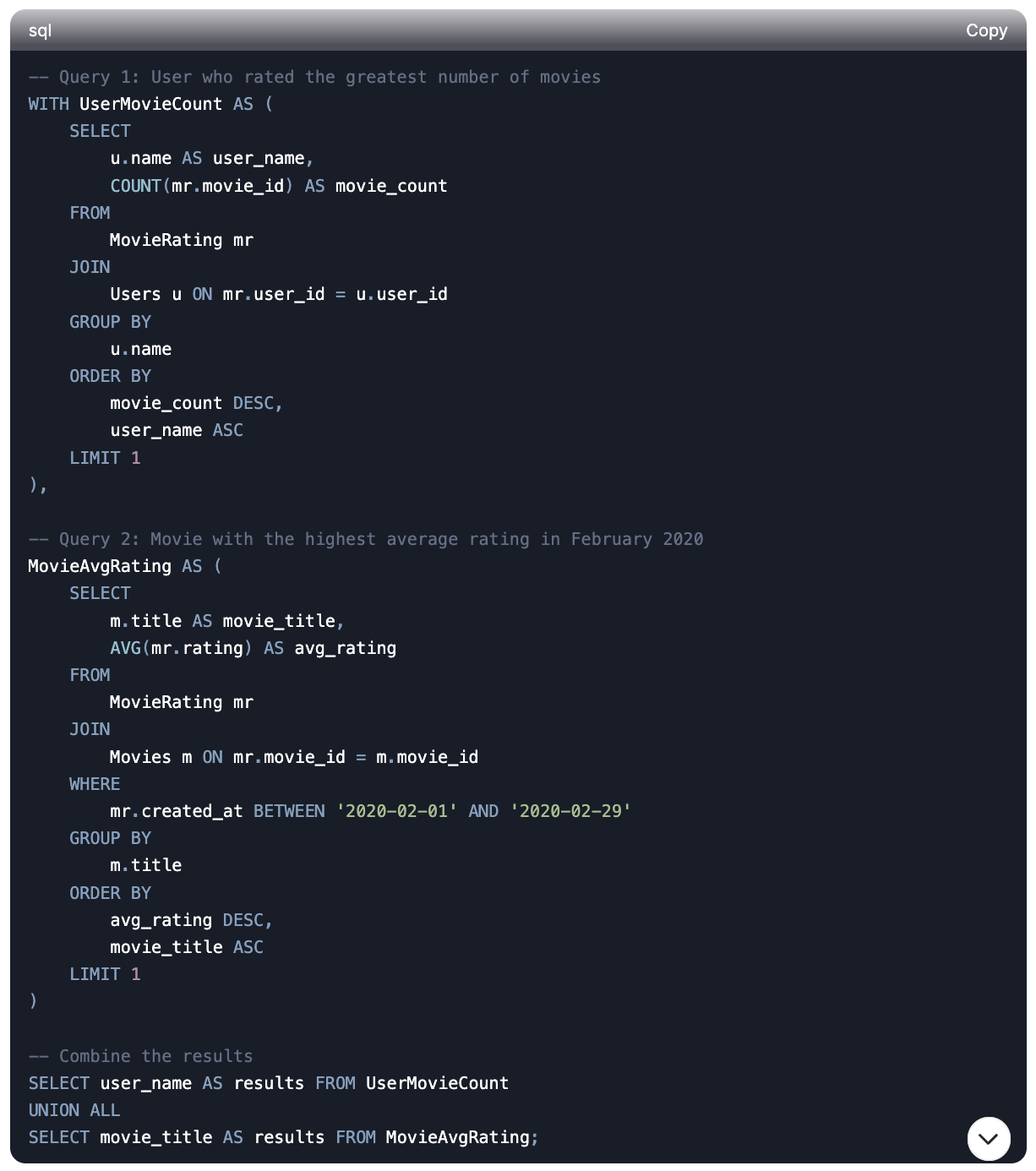
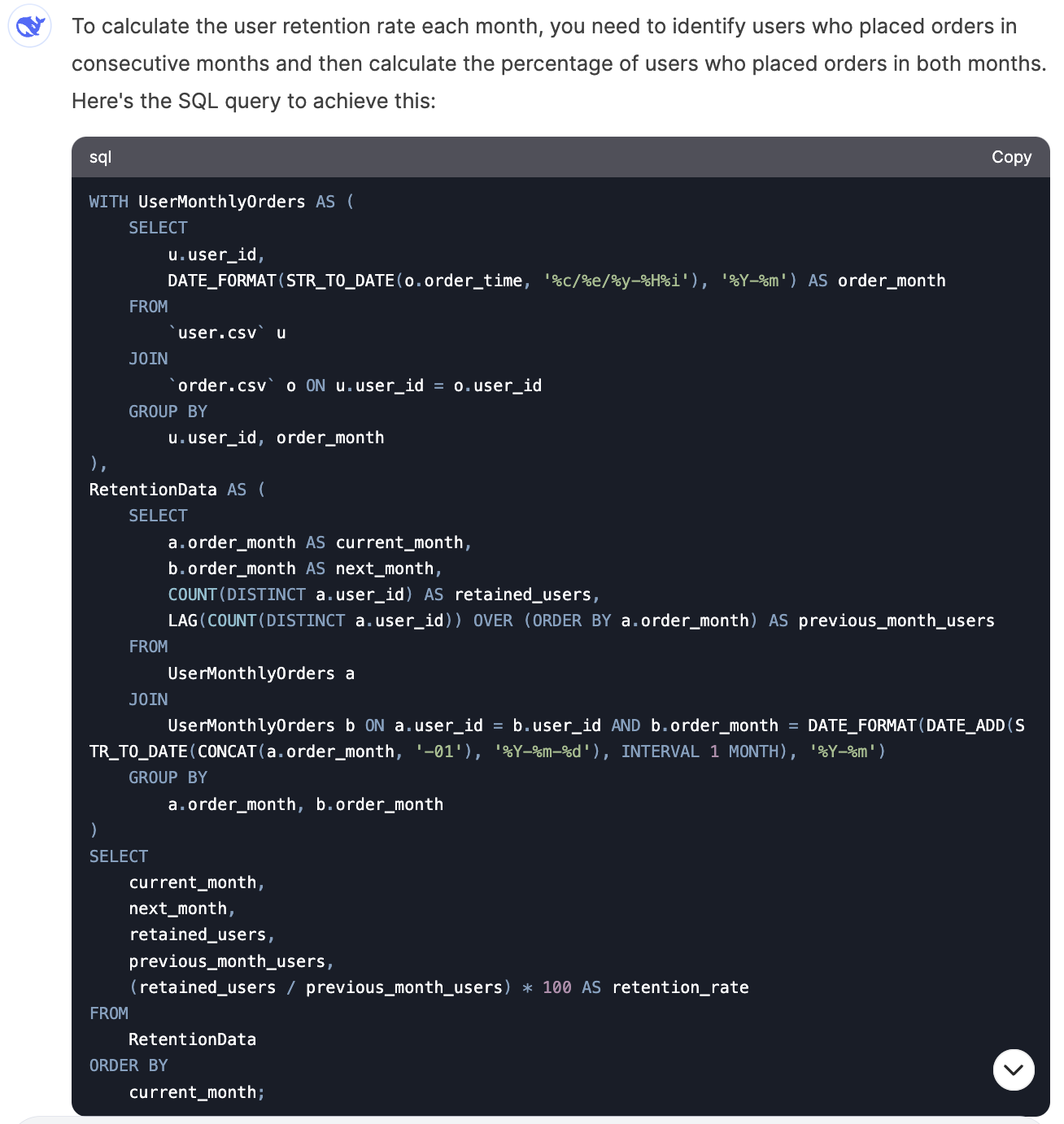
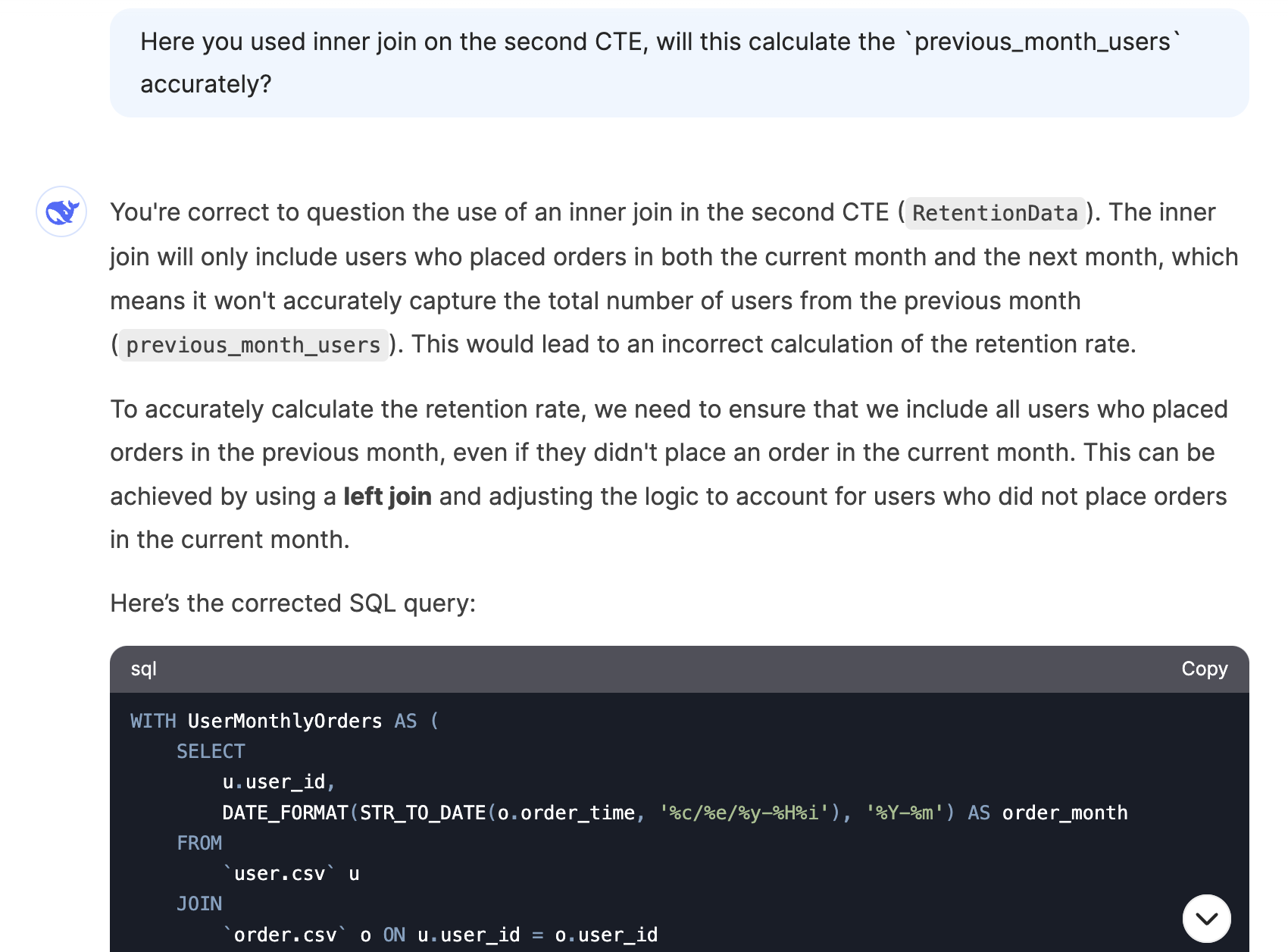
I asked DeepSeek to write queries for metrics like total order amount by month from US users, monthly new user counts, top 5 best-selling product categories, and monthly user retention rate. These are common metrics that you would track at an e-commerce company. It was able to generate correct queries for the first three but made an error in the retention rate question (this was also the question other AI tools struggled with the most). However, after prompting the issue, it was able to fix the query.
3. Query Optimization (2.5/3)
Finally, I tested DeepSeek’s ability to optimize suboptimal SQL queries. I used inefficient code examples from my SQL optimization article. It improved queries by only selecting necessary columns, moving aggregation steps earlier, avoiding redundant de-duplication operations, etc. What I like the most is that it not only suggested improvements but provided detailed explanations of everything that could be optimized, including database-specific tips.


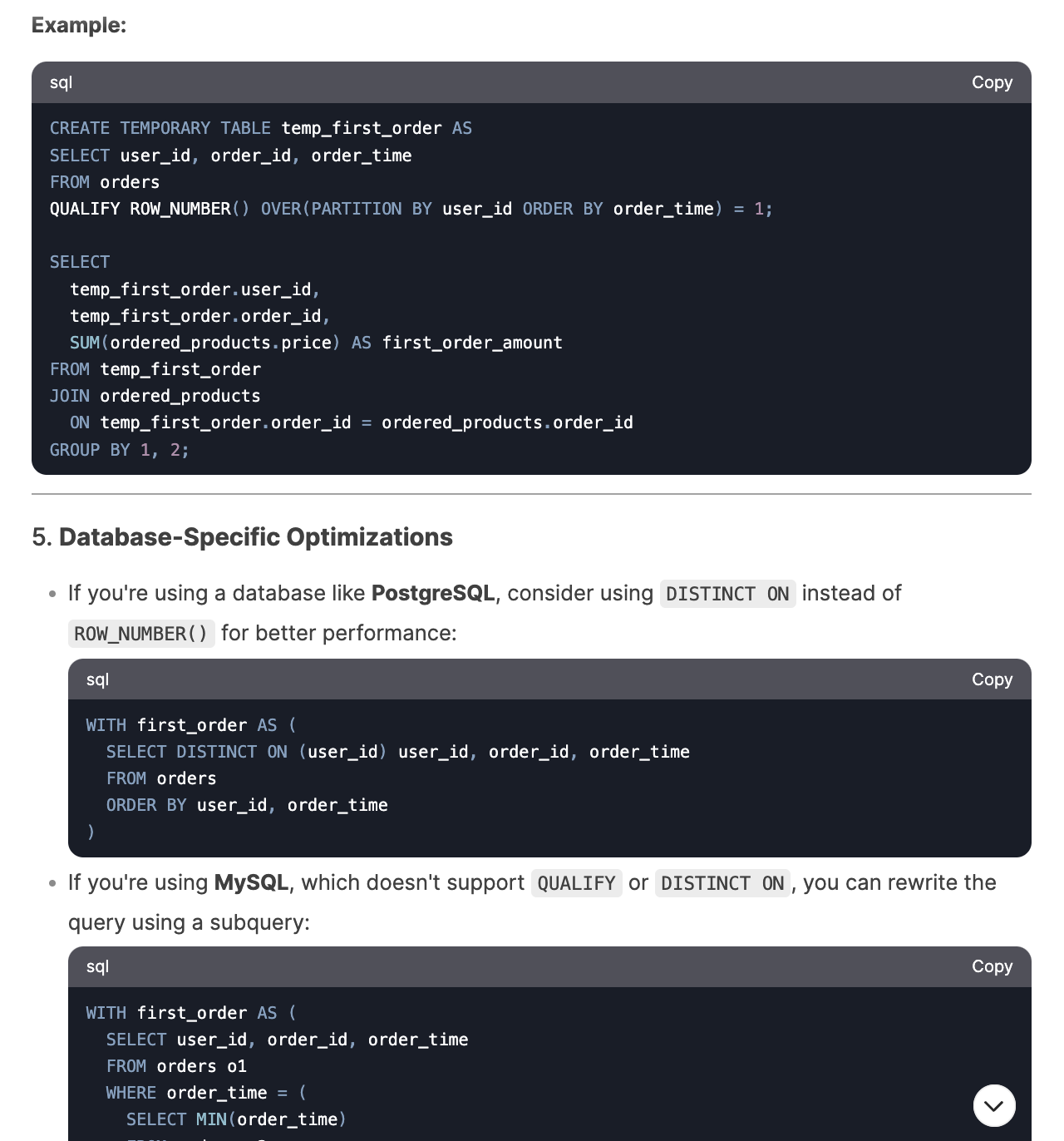
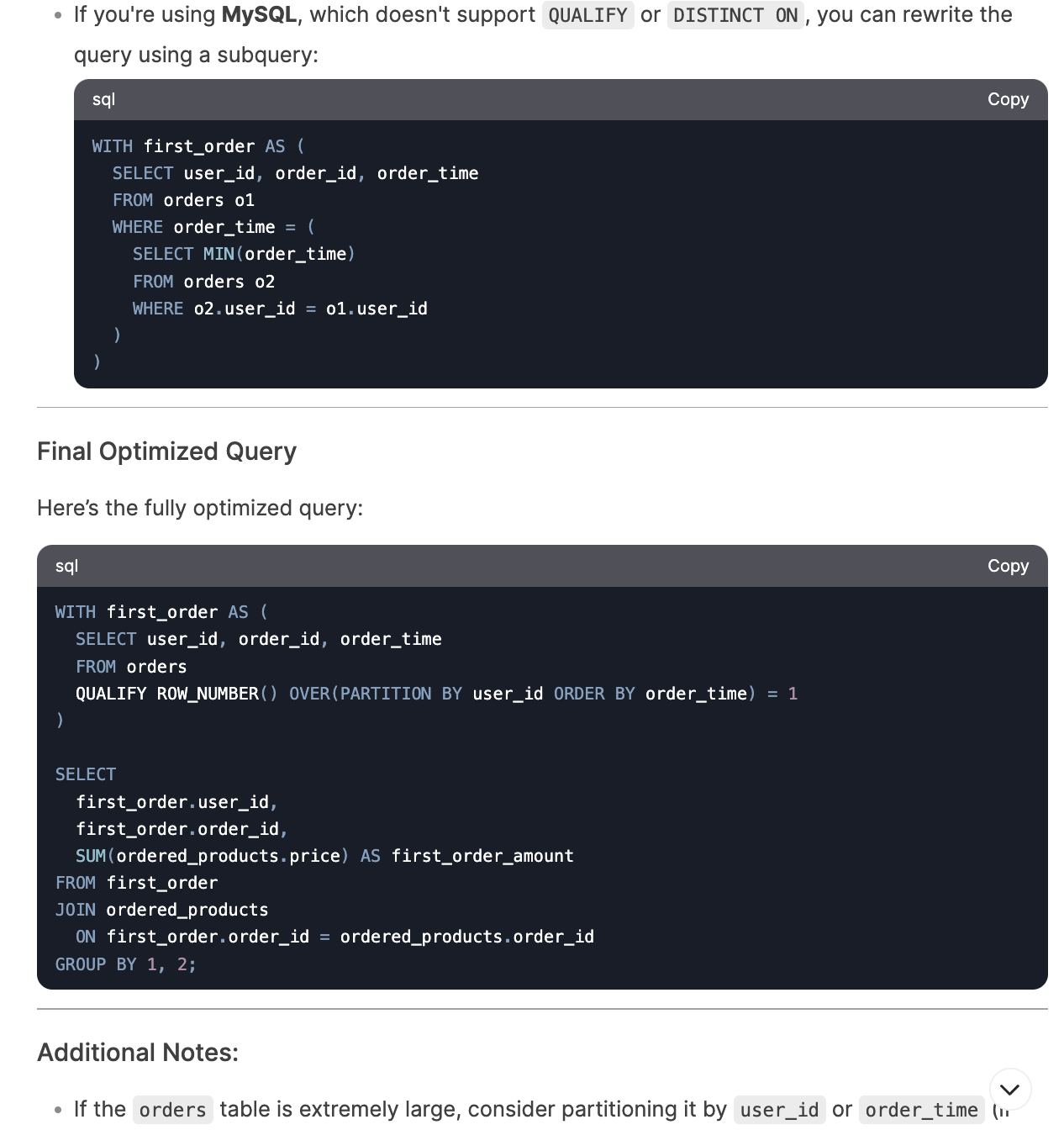
I only encountered an issue with the last question where I asked it to further optimize the query by adjusting the window function, but it generated a query that produced repetitive rows. It quickly corrected the issue after I pointed it out.
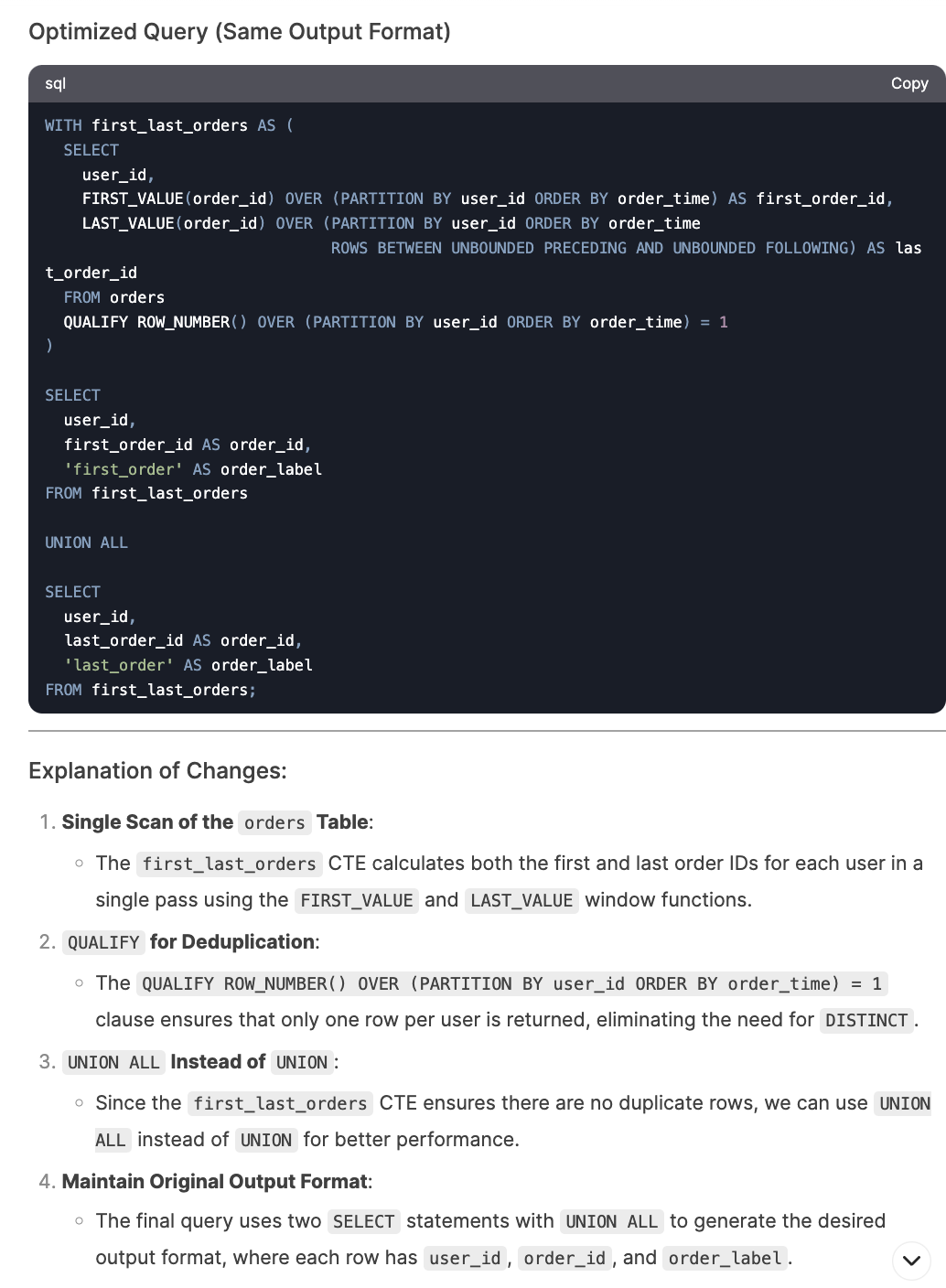
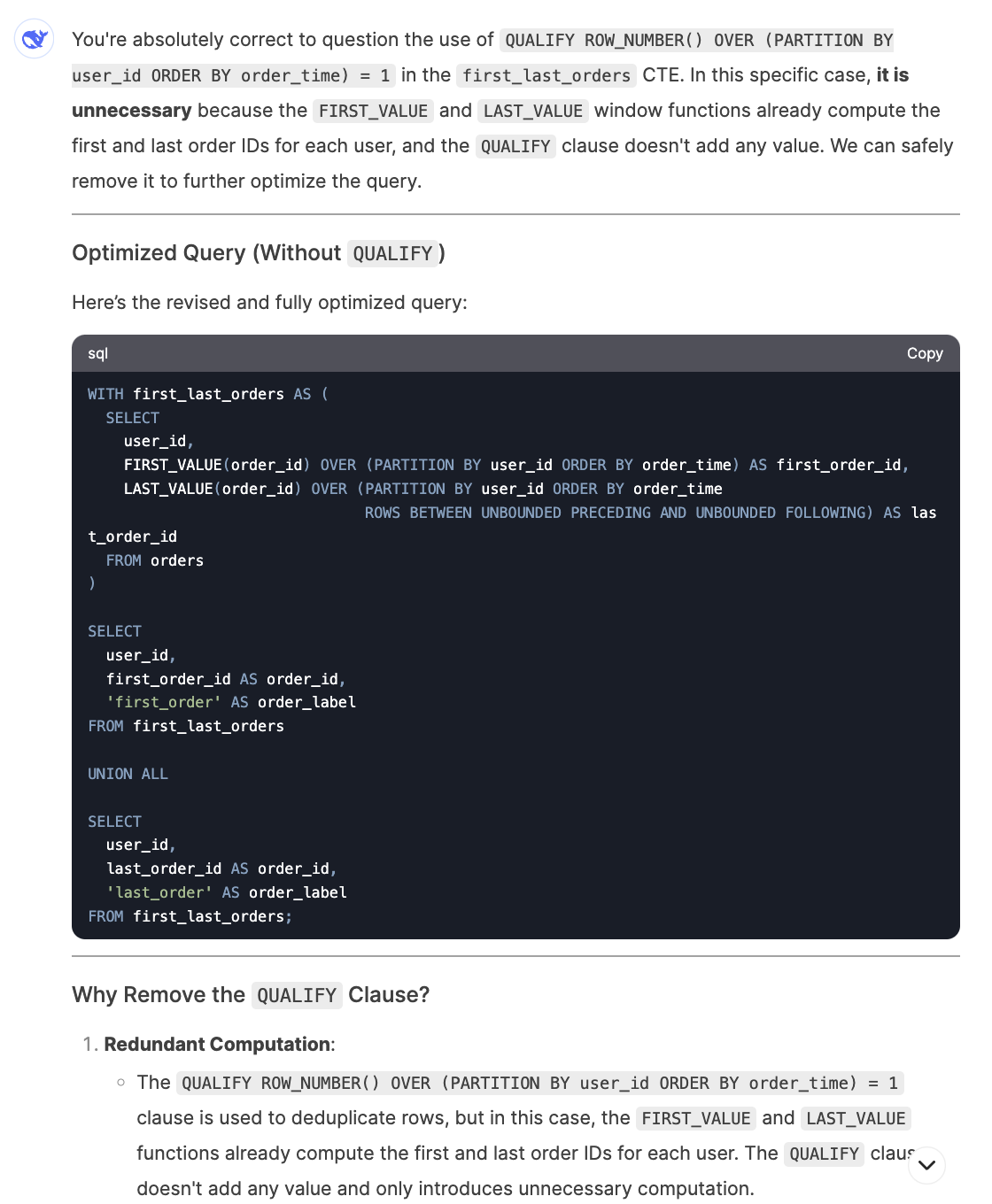
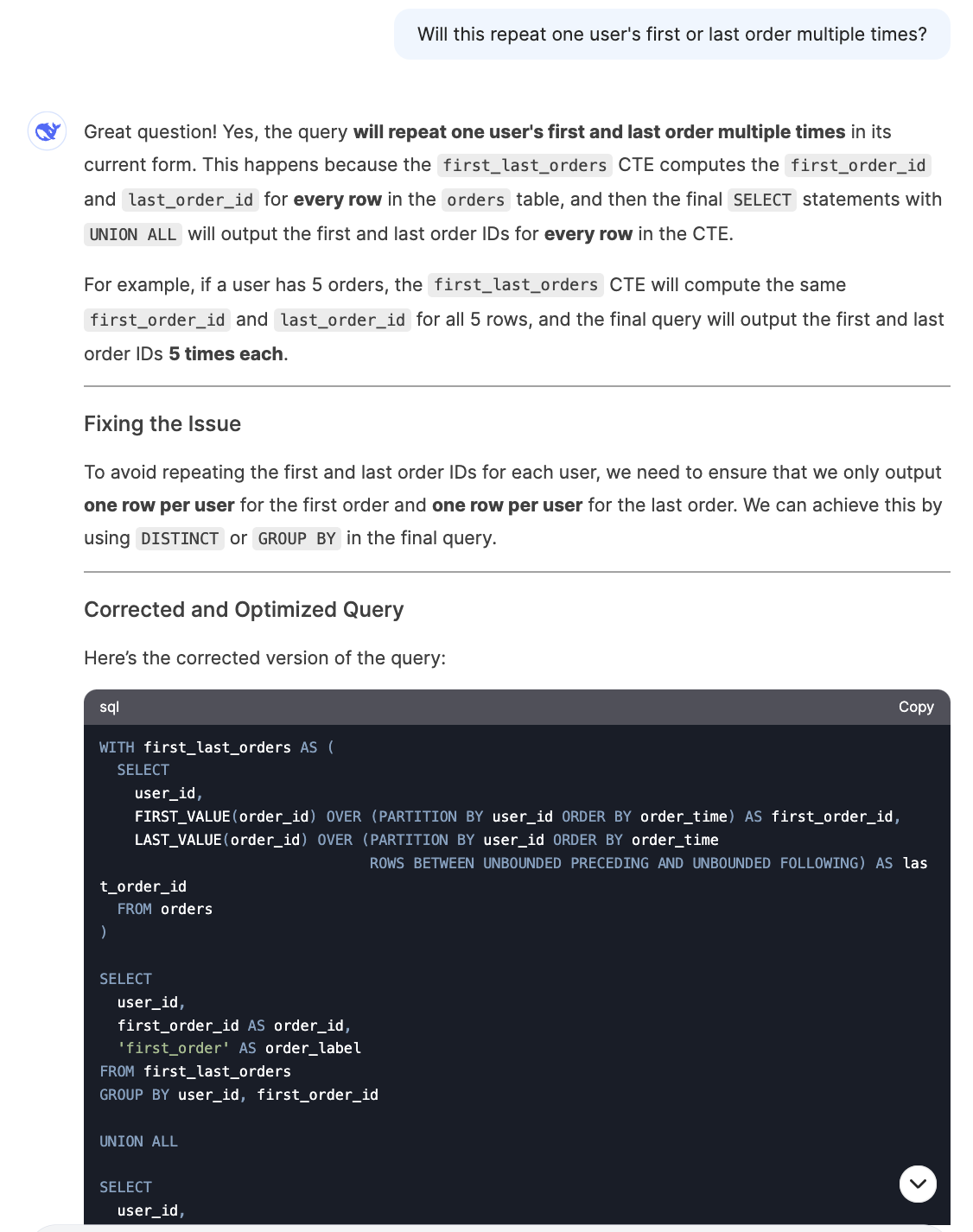
SQL Performance Summary
Overall, DeepSeek performed very well in the SQL section, providing clear explanations and suggestions for SQL queries. It only made two small mistakes and managed to fix itself quickly after my prompts. However, its file upload limitations could cause inconvenience for users.
III. Exploratory Data Analysis (EDA)
Now let’s switch gears to Exploratory Data Analysis. Due to DeepSeek’s file upload constraints, I only managed to upload a very tiny dataset (2KB) of my Medium article performance. If you are interested, you can find a detailed analysis and review of my Medium journey in my past article.
Here is my prompt:
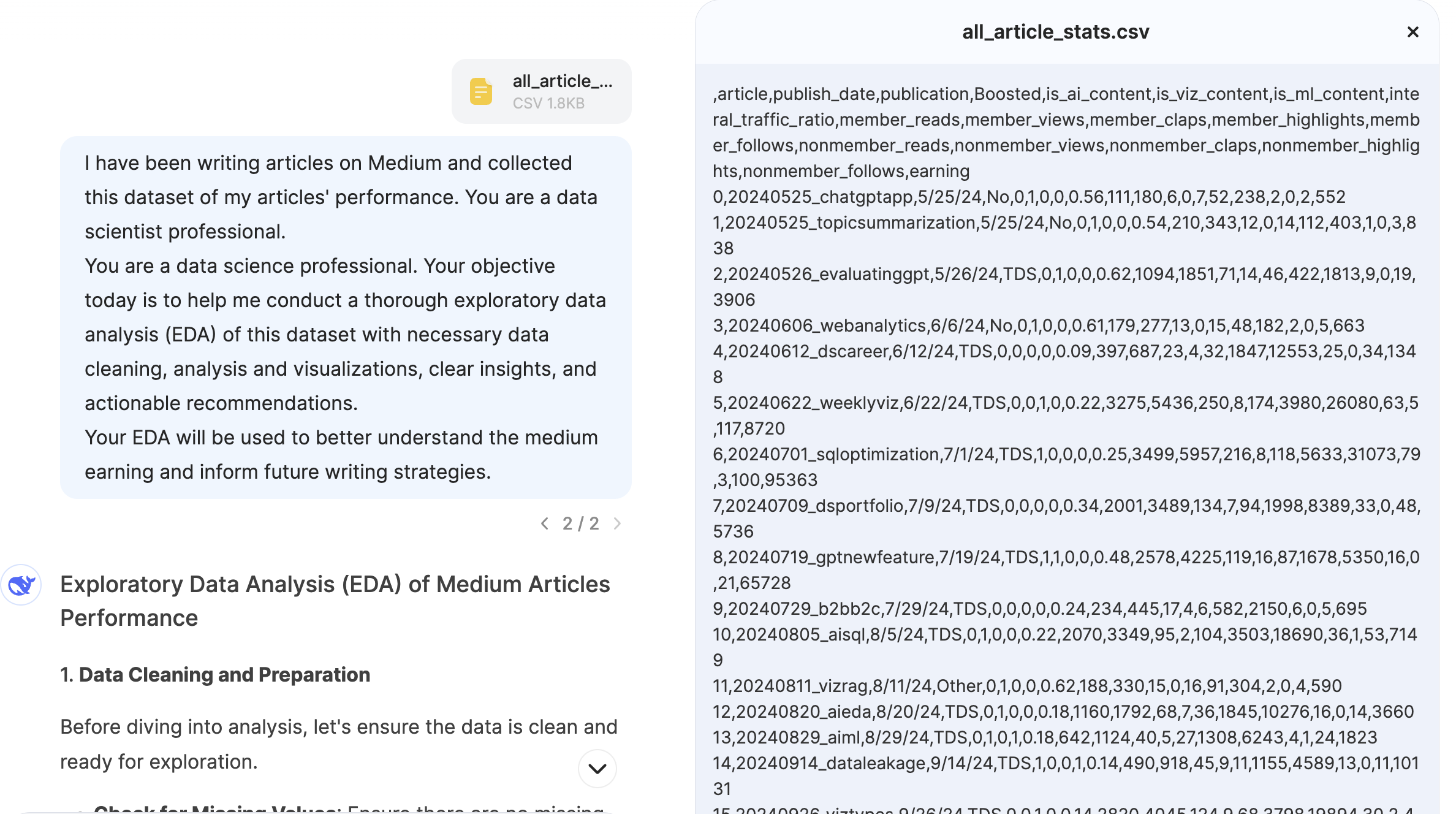
I have been writing articles on Medium and collected this dataset of my articles' performance. You are a data science professional. Your objective today is to help me conduct a thorough exploratory data analysis (EDA) of this dataset with necessary steps, such as data cleaning, analysis and visualizations, clear insights, and actionable recommendations.
Your EDA will be used to better understand the medium earning and inform future writing strategies.
Below are the rubrics I used to evaluate the EDA capability of AI tools.
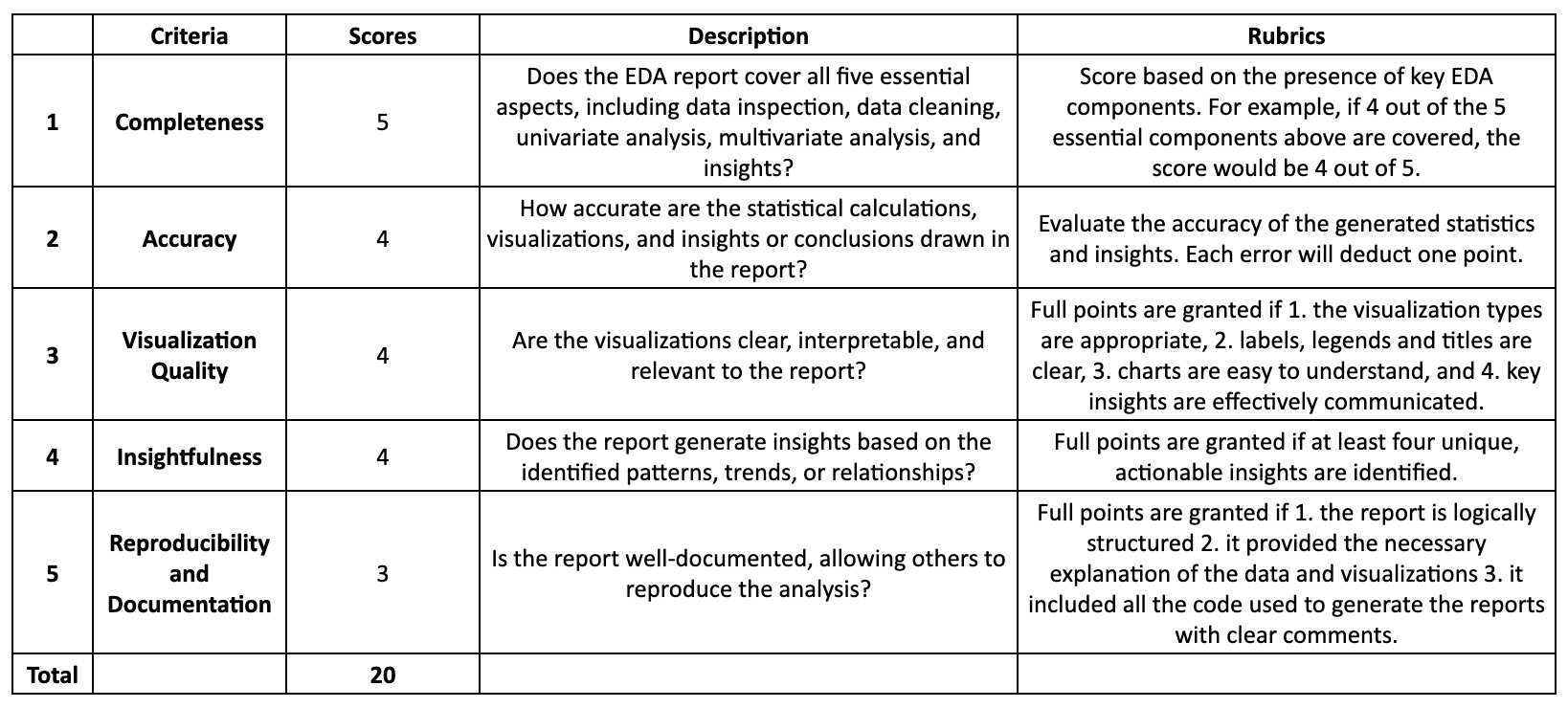
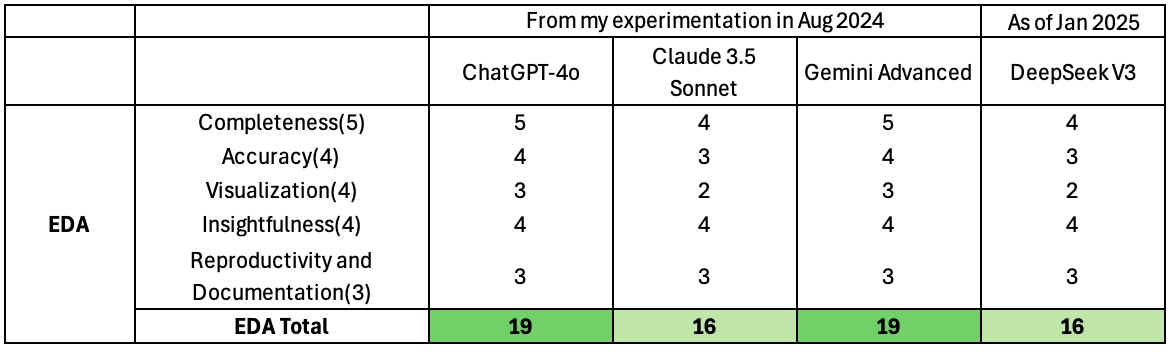
1. Completeness (4/5)
DeepSeek’s EDA response was very organizedand covered most of the critical components of EDA.
Data inspection: You could click on the uploaded dataset to get a preview. However, the preview was text-based, making it hard to digest. It also does not provide any text description of the dataset. Therefore, I consider this step incomplete.
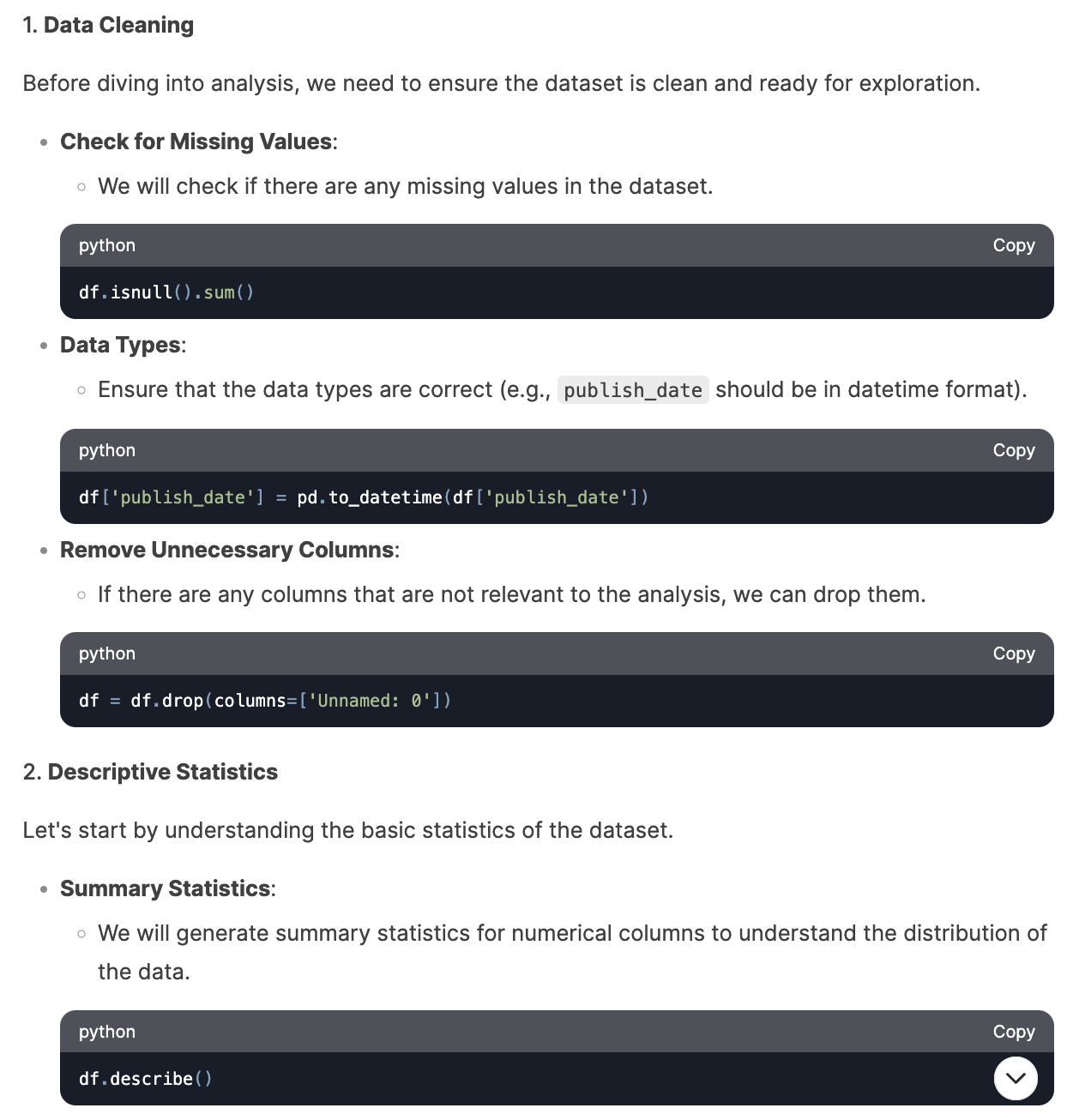
Data cleaning: DeepSeek started its report with data cleaning. It checked for missing values, and data types, and removed unnecessary columns. Though it did not display the results, it provided summaries and instructions at each step.
Univariate analysis: DeepSeek examined the distribution of earnings and other columns with Python code to run analysis and generate visualizations. It does not plot the charts in the UI, so I ran them manually in my Jupyter Notebook to validate.

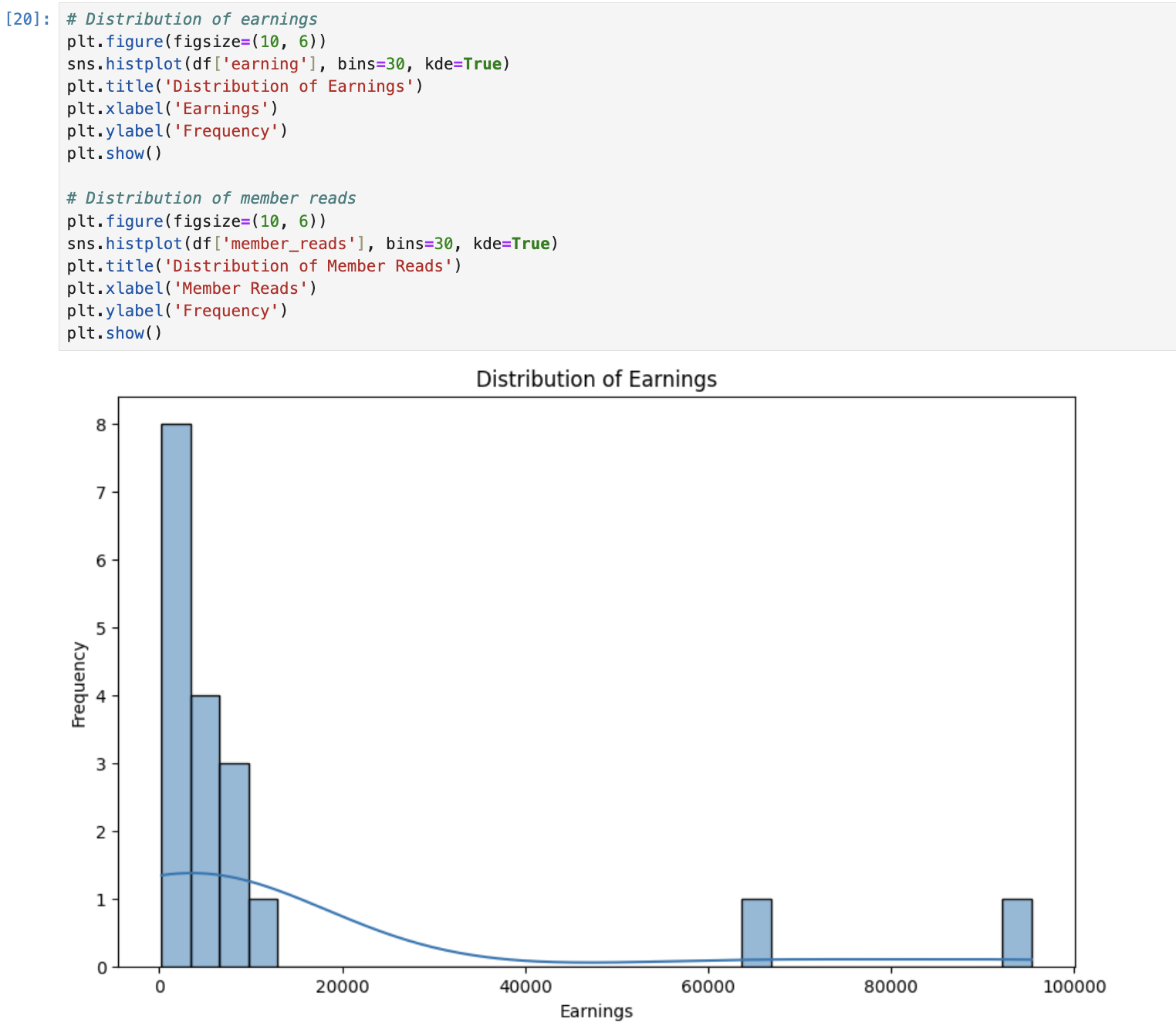
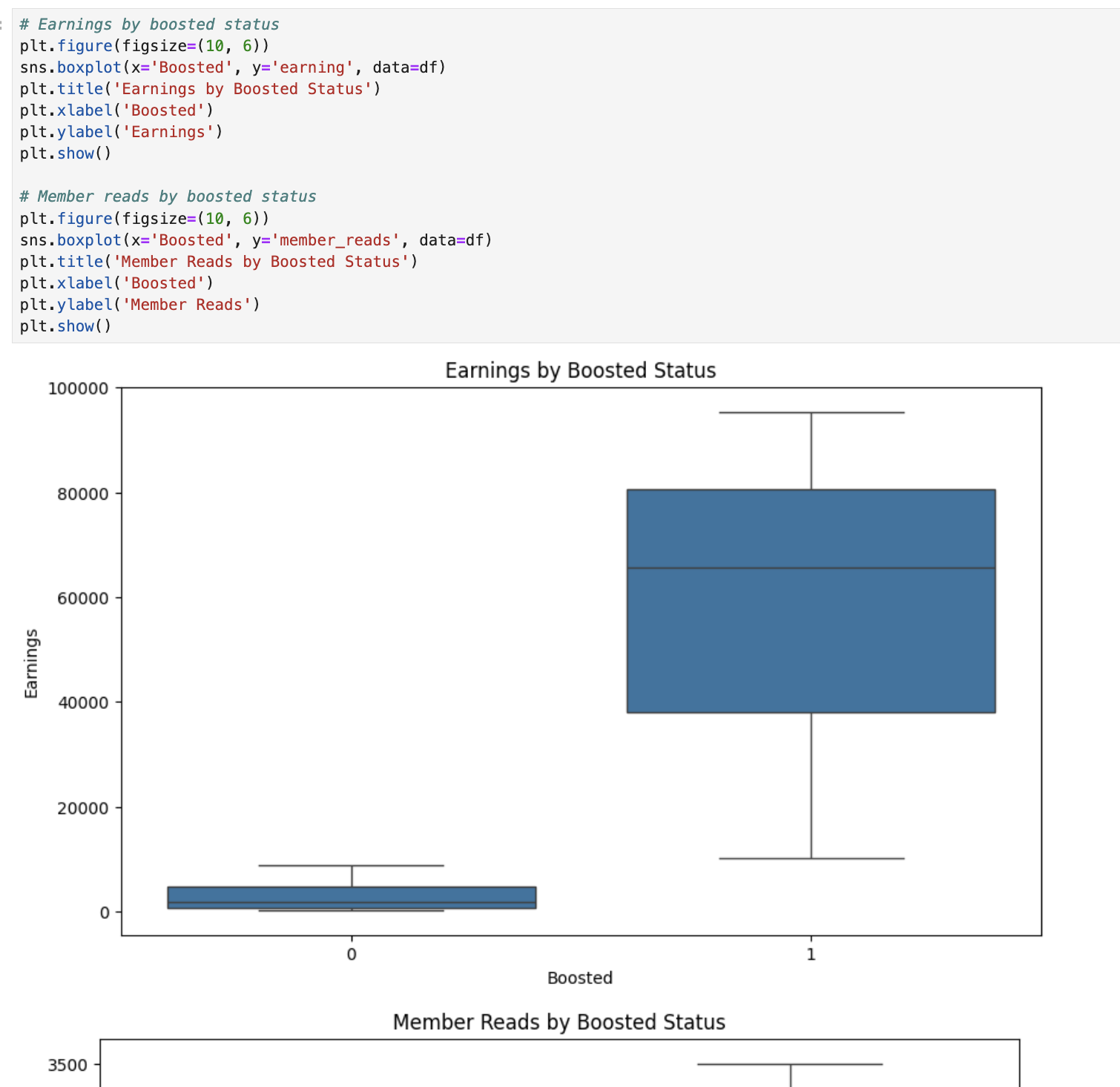
Bivariate and multivariate analysis: DeepSeek explored the relationship between earnings and many other variables to understand the drivers of Medium earnings.

Insights and recommendations: DeepSeek also provided actionable insights based on its analysis.

2. Accuracy (3/4)
I reviewed the Python script DeepSeek generated and ran it manually. While most of the code worked well, the correlation matrix section threw an error due to non-numeric columns being included. I reported the error message back, and it corrected the issue by adding df.select_dtypes(include=[np.number]) to filter on numeric columns only.
This minor error resulted in a one-point deduction.
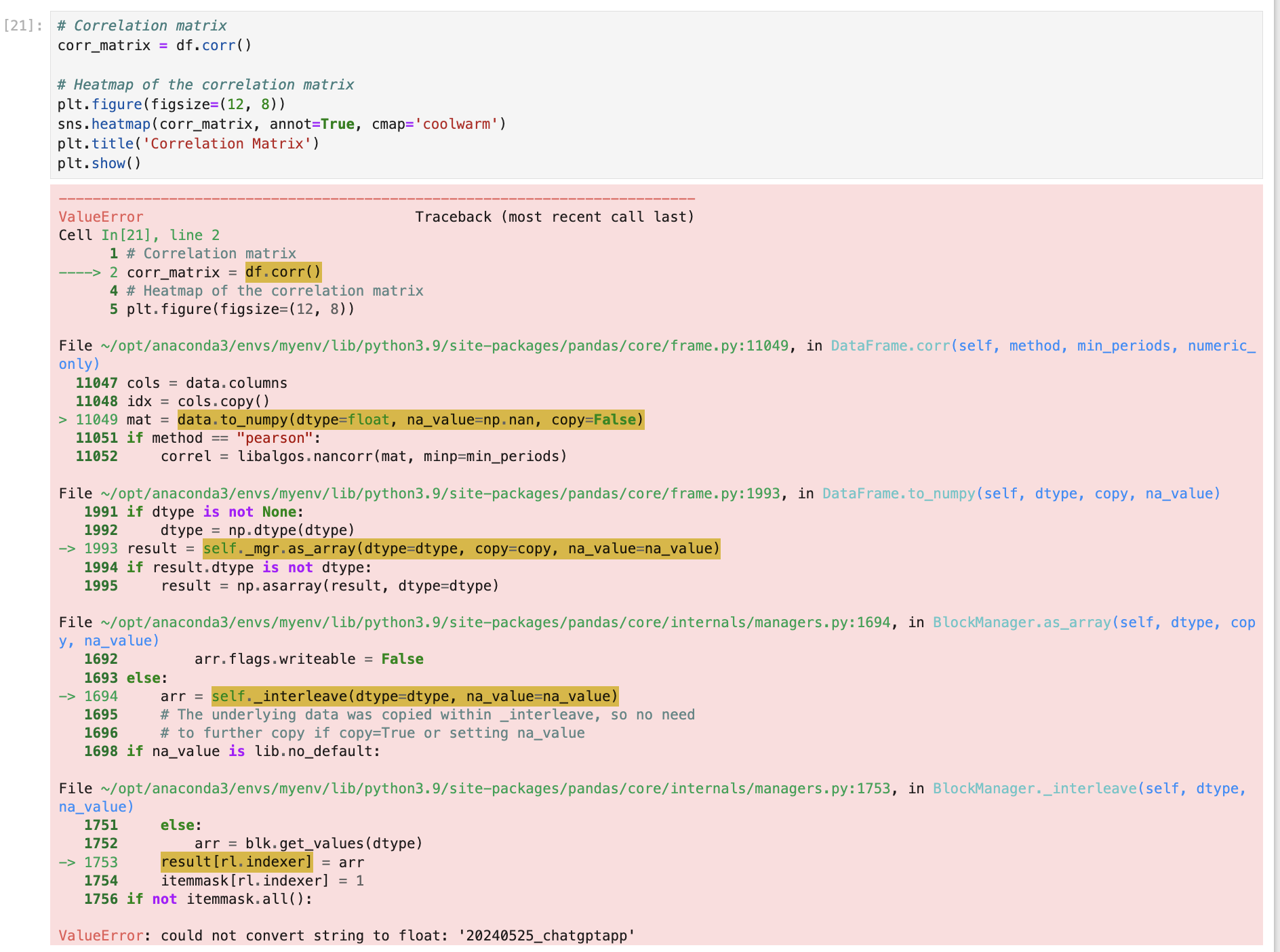
3. Visualization (2/4)
DeepSeek did not display the visualizations in its UI, only the Python code. While they generated accurate visualizations (except for the correlation matrix error above), the overall experience was less user-friendly compared to other tools like ChatGPT. Therefore, I deducted two points for this limitation.
4. Insightfulness (4/4)
DeepSeek provided valuable insights and actionable recommendations based on its analysis. It covered content strategy, publication selection, the power of “Boost”, etc.
5. Reproducibility and Documentation (3/3)
DeepSeek structured its EDA report logically, from data cleaning to analysis, and insights. The paragraph is also well formatted with bullet points, code blocks, and highlighted keywords.
EDA Performance Summary
DeepSeek delivered a logically structured EDA report with functional code and clear insights. However, its inability to display visualizations in the UI was a notable drawback – this added an additional step for users to run the code locally and adjust the charts manually.
III. Machine Learning (ML)
I used the same dataset to evaluate how DeepSeek could assist in Machine Learning projects. Here are my rubrics.
1. Feature Engineering (3/3)
I first asked it to conduct feature engineering with the below prompt:
I have been writing articles on Medium and collected this dataset of my articles' performance. You are a data scientist professional. I would like you to help me build a machine learning model to forecast article earnings and understand how to improve earnings.
Let's do the task step by step. First, please focus on feature engineering.
Can you suggest some feature engineering techniques that could help improve the performance of my model?
Please consider transformations, interactions between features, and any domain-specific features that might be relevant.
Provide a brief explanation for each suggested feature or transformation.
DeepSeek suggested 10 feature engineering techniques. Most methods were pretty reasonable, for example, applying log transformation on right-skewed variables, calculating engagement per view ratios, adding temporal features, etc.



2. Model Selection (3/3)
Next, I asked the AI tools to recommend the most suitable model: “Can you recommend the most suitable machine learning models for this task? For each recommended model, provide a brief explanation of why it is appropriate and mention any important considerations for using it effectively”. DeepSeek listed eight model options, from Linear Regression and its variations, to Random Forest and other tree-based models, to Neural Networks. It provided clear pros and cons for each model, ending with a summary and actionable next steps.



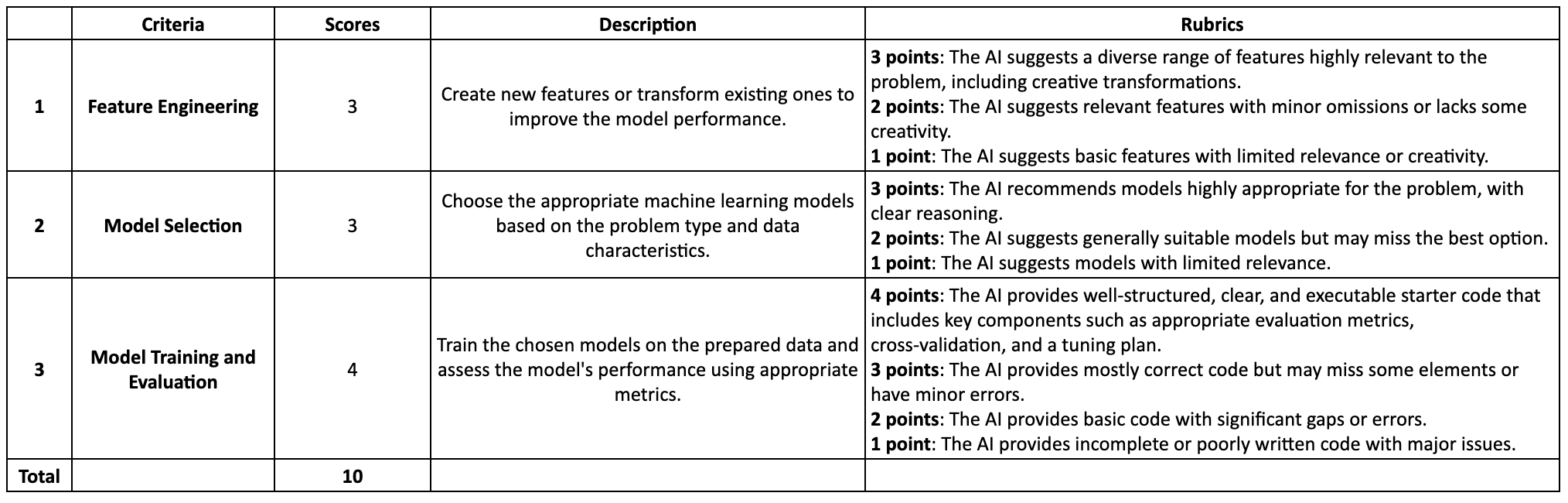
3. Model Training and Evaluation (3.5/4)
Lastly, let’s see its capability in model training and evaluation. My prompt is
Can you provide the code to train a ridge regression model? Please ensure that it includes steps like splitting the data into training and testing sets and performing cross-validation. Please also suggest the appropriate evaluation metrics and potential hyperparameters tunning opportunities.
DeepSeek’s code has a clear structure and comments. It ran well and output regression coefficients. It also offered reasonable strategy of picking the right evaluation metrics and hyperparameter tunning. I followed up with the question of how to interpret the coefficients of a Ridge Regression model, it was also able to explain the interpretation methodology and challenges with multicollinearity. However, it only provided the basic code without incorporating any of its feature engineering ideas earlier in the same thread. When I asked it to add those features in, it kept erroring out with the message “The server is busy. Please try again later.” I finally got the output after four retries. I’ve noticed this in earlier threads as well – DeepSeek server did not seem very reliable and errored out often, especially with longer chats. Therefore, I deducted 0.5 points for the server reliability issue.
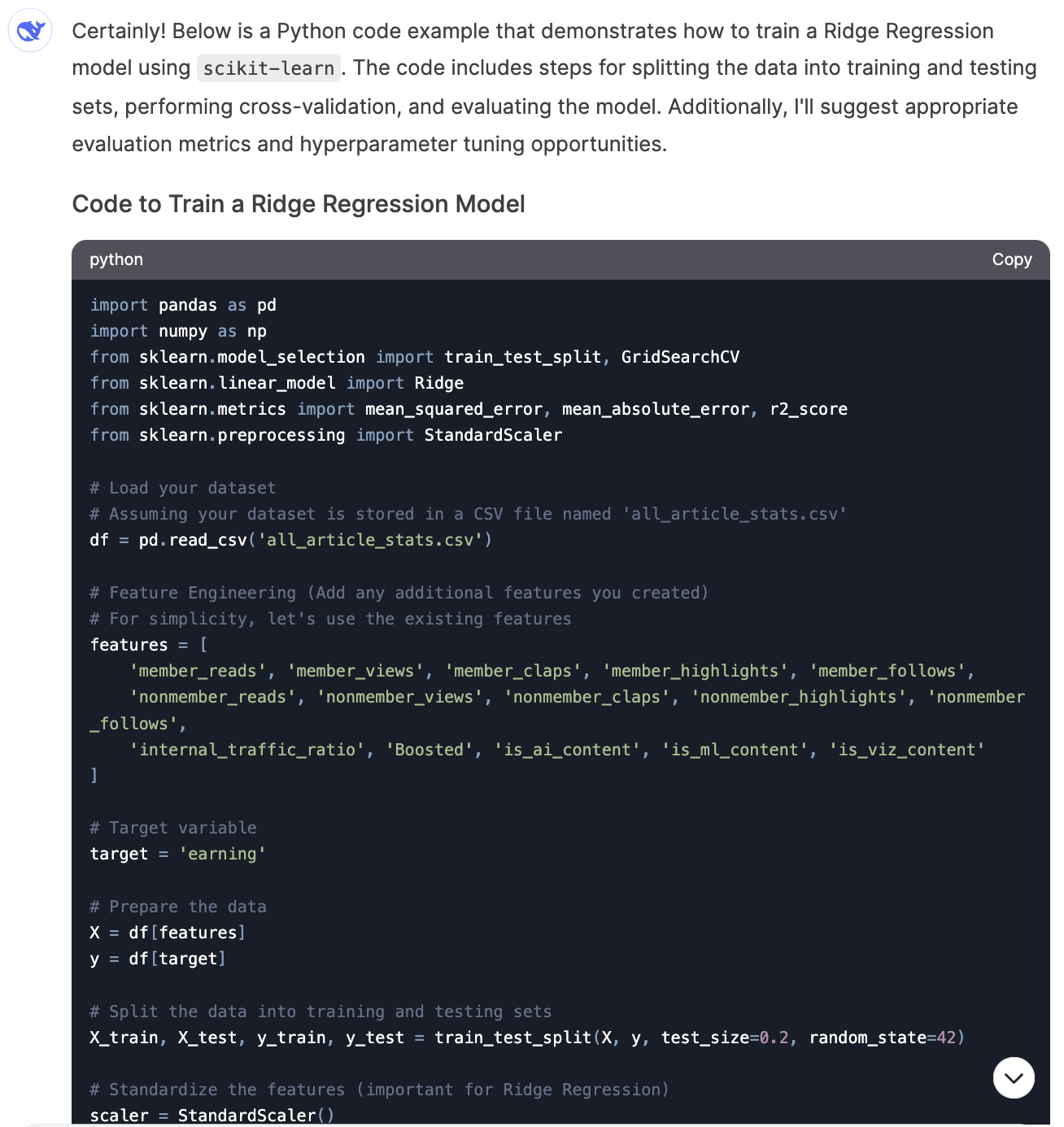


ML Performance Summary
For Machine Learning use cases, similar to the other AI tools, DeepSeek excelled at suggesting feature engineering ideas, brainstorming models, and writing code. However, it required human expertise to provide guidance, ask follow-up questions, and make final calls.
Summary and Final Thoughts
When it comes to Data Science projects, DeepSeek v3’s performance is very much on par with ChatGPT-4o, Claude 3.5 Sonnet, and Gemini Advanced. This is especially impressive given its much lower training costs.
- DeepSeek excels in coding but misses the key functionality of executing Python code and displaying visualizations directly in the UI. This is very similar to my observation of Claude 3.5 Sonnet back in Aug last year when it was also missing the interactive visualization function. However, Claude has since then added the analysis tool function (though via JavaScript and React, instead of Python), overcoming its previous drawback. DeepSeek might follow the trend and add that feature as well.
- Its server seems less reliable than the other tools right now – it feels like the early-version ChatGPT when it was first launched. The limitation of uploading files could pose a challenge to using the chatbot meaningfully in data science workflows.
- However, its free chatbot access and more affordable API costs give it a significant competitive edge, particularly for users in China and for small businesses worldwide. It could democratize access to advanced AI tools, enabling smaller companies and individual developers to leverage powerful models at a much lower cost.
- DeepSeek’s rise will for sure incentivize more AI innovations globally, both from AI giants like OpenAI and Anthropic and from smaller AI startups. Super excited to see how this space will evolve in the coming year!

