
Evaluating ChatGPT in Data Science: Churn Prediction Analysis As An Example
Introduction
It has been a while since GPT launched its data analysis capability. As promised (last year), I am writing this post to assess its capabilities in aiding (or even replacing) a data scientist, and its limitations.
To complete this task, I asked GPT to perform a very common DS project in real life – churn prediction. It is one of the core problems for many businesses and an area that has seen a lot of data science use cases. I found this Online Retail Customer Churn Dataset from Kaggle, which contains various customer demographics and engagement data and a clean target column of churn or not. Here is my complete prompt to ChatGPT:
You are a professional data scientist working at an online retail company.
You have this dataset that provides a comprehensive overview of customer interactions with the online retail store.
It includes data on customer demographics, spending behavior, satisfaction levels, and engagement with marketing campaigns. Your aim is to analyze this dataset to predict customer churn, enabling targeted customer retention strategies.
Below is the column description:
Customer_ID: A unique identifier for each customer.
Age: The customer's age.
Gender: The customer's gender (Male, Female, Other).
Annual_Income: The annual income of the customer in thousands of dollars.
Total_Spend: The total amount spent by the customer in the last year.
Years_as_Customer: The number of years the individual has been a customer of the store.
Num_of_Purchases: The number of purchases the customer made in the last year.
Average_Transaction_Amount: The average amount spent per transaction.
Num_of_Returns: The number of items the customer returned in the last year.
Num_of_Support_Contacts: The number of times the customer contacted support in the last year.
Satisfaction_Score: A score from 1 to 5 indicating the customer's satisfaction with the store.
Last_Purchase_Days_Ago: The number of days since the customer's last purchase.
Email_Opt_In: Whether the customer has opted in to receive marketing emails.
Promotion_Response: The customer's response to the last promotional campaign (Responded, Ignored, Unsubscribed).
Target_Churn: Indicates whether the customer churned (True or False).
Please run the analysis and give the code you used, and more importantly, provide actionable data insights and business recommendations.
ChatGPT Response
Below is ChatGPT’s response. Please note these are all from one response, but I broke it down for better readability (and I could not make a screenshot this long…).
1. Approach and Methodology
Firstly, ChatGPT outlined a six-step analysis process. This makes total sense to me, but my only comment is – usually analysis is more of an iterative process. In step 6, you always need to collect feedback from stakeholders and go back to earlier steps. For example, they might have ideas of additional features you want to collect or suggest new hypotheses you want to validate with your dataset.

2. Exploratory Data Analysis
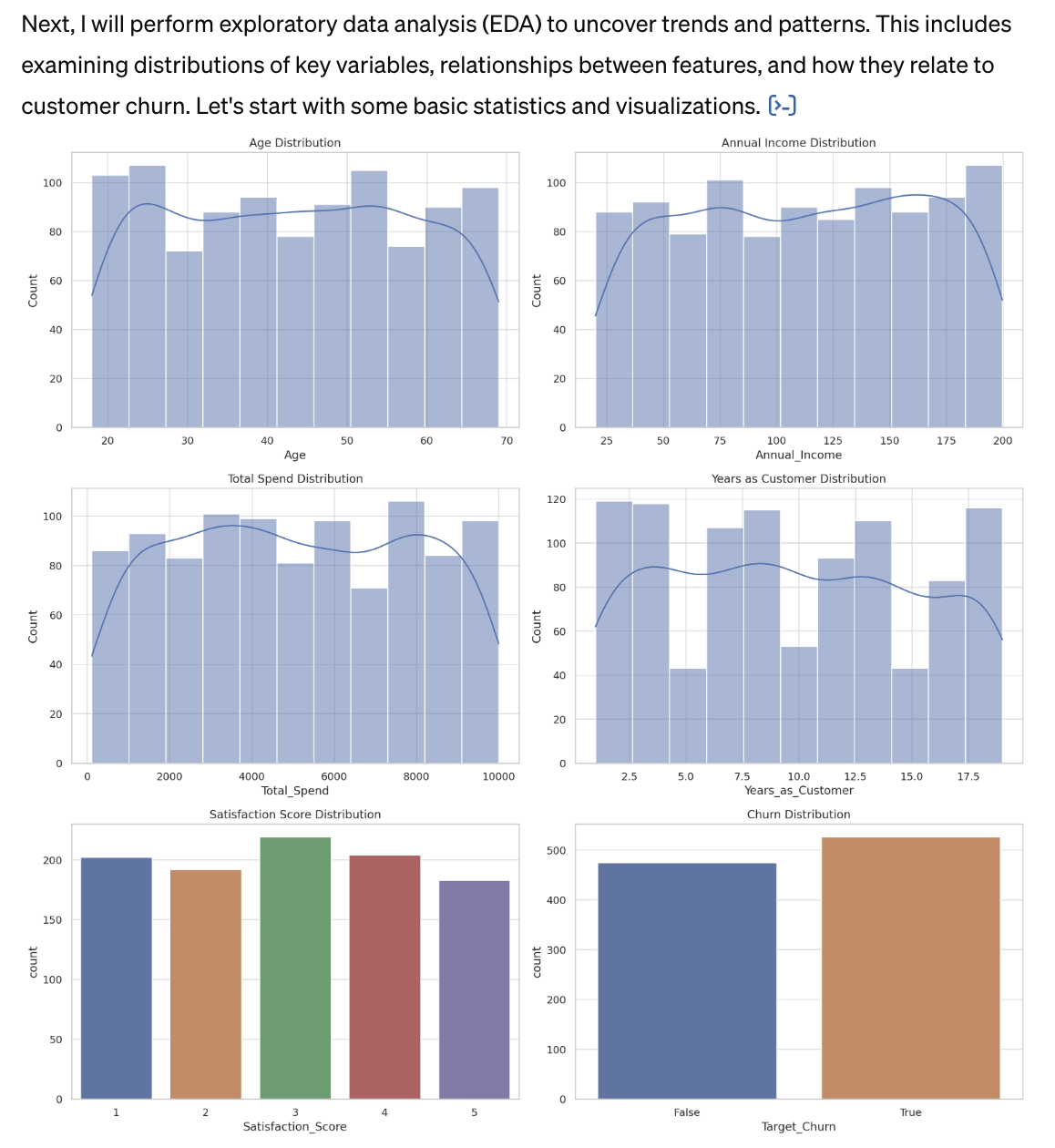
Next, ChatGPT went straight to the EDA step as it recognized the dataset provided is pretty clean with appropriate data types and no missing values (I am glad it checked and mentioned this). It first looked at the distribution of each feature with histograms and bar charts and provided some observations. This step is important in data science practices as it helps to understand your dataset better.

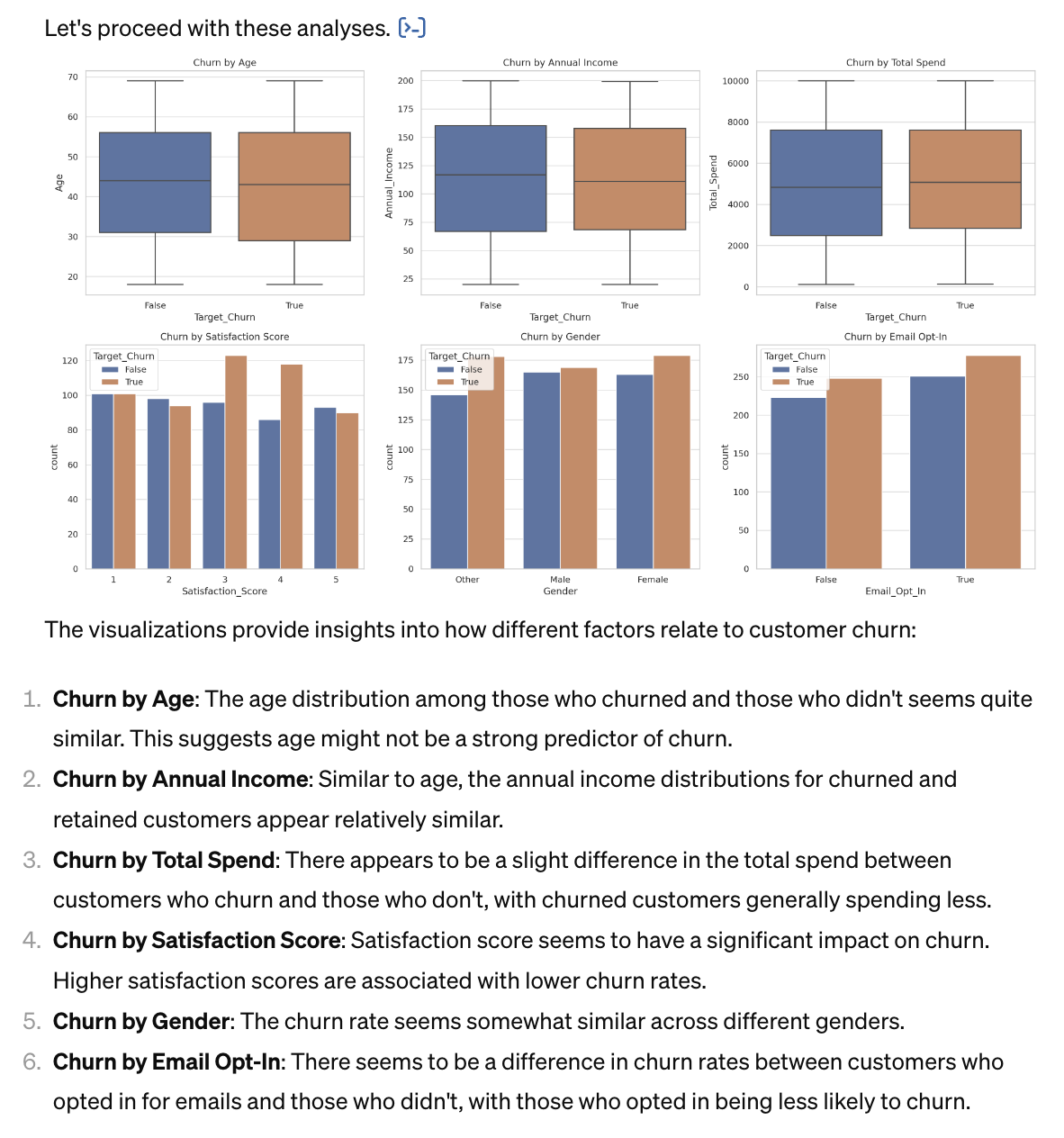
Then it conducted a univariate analysis of each feature against our target (churn). Here it explained how different factors relate to customer churn with actionable insights. While the insights were pertinent, there are two obvious things it can improve: 1. Univariate analysis is good for initial exploration, but it ignores the relationship between the variables with the risk of oversimplification and misleading conclusions, plus correlation is not causation. 2. Some of the feedback is a bit broad, so not 100% actionable from a business standpoint (e.g. “Focus on Customer Satisfaction”).

3. Modeling
ChatGPT proceeded to predict customer churn with a Random Forest model and provided the confusion matrix. I would say the model choice is appropriate – tree-based model is also my go-to-model when handling this type of problem (though I might prefer CatBoost more these days). However, we all know that calling the classifier in sklearn with all the raw features and default parameters is only the very first step of model development. ChatGPT is only doing the bare minimum here, but it’s already very impressive as part of its long answer.

4. Recommendations and Next Steps
Last but not least, it wrote a summary with business recommendations and next steps, which includes some of the potential improvements we have mentioned above like model improvements.

5. Follow-up Questions
I also sent it some follow-up questions, just as we always get questions when presenting the analysis to our cross-functions. ChatGPT adequately addressed them, offering theoretical perspectives but sometimes missing practical nuances.



Summary
So, how would you rate the analysis of our data scientist Mr. Bot here? For me, I would say, it reminds me of the analysis report I wrote as a class assignment when I was in school – we were always given a clean dataset and a clear objective, and an analysis report with clear steps and reasonable recommendations just like this should get a good score.
However, there is still a visible gap between this and the nuanced challenges faced by data scientists. Below are the strengths and limitations I have observed from this small experiment.
Strengths
- Logical process with visualizations and code: ChatGPT analyzed with a well-defined framework and step-by-step explanations. It also attached the code and the visualizations generated, which makes it super easy to copy-paste over and iterate on top of it.
- Reasonable insights and recommendations: It provided multiple relevant insights and recommendations from the analysis result, though they sometimes lack the depth and specificity necessary for actionable business strategies.
- Clear next steps: The next steps it provided could inspire further deep-dive into the dataset, model iterations, conversation with stakeholders, etc. You can also ask follow-up questions by simply chatting with it.
Limitations
- Gap in data preparation: Usually in the real world, having a clean dataset is a luxury, and already 80% of the project. We always need to go deep into the database/data warehouse/data lake/data lakehouse (…), ask around, and even build new data pipelines to collect all the data we need. It is also not realistic (at least today) to grant OpenAI access to our data and ask it to write queries and collect the features itself, given the complexity of real-world data infra and data privacy concerns. I have read some articles proposing architecture to enable this process, and some tools trying to solve this problem, but overall it is still not feasible right now.
- Basic methodology: In this project, I didn’t tell ChatGPT what methods to use. It is able to choose the appropriate method but lacks the sophistication required for advanced data analysis. For example, it only did univariate analysis without considering correlations among features; and it did a basic random forest forecast without feature engineering and tunning parameters. Therefore, guidance from a professional is needed to make sure the output is statistically sound with the best approach.
- Data size and I/O limitation: The toy dataset I am using here only has 1000 rows and 15 columns. But for a real churn prediction project, you are usually working with a dataset that’s at least 100x larger. Therefore, you can easily hit the limit of ChatGPT context window, and not be able to ask it to output something like a processed dataset or predictions to you. A more practical use case is to describe the dataset you have and the problem you are trying to tackle and ask it to generate code for you.
- Lack of domain knowledge: ChatGPT is already very smart with lots of business knowledge in its ‘mind’. However, every business has its unique situation and focus, and each project has its own objective and nuance. It is hard to just teach GPT everything it needs to know to provide recommendations that are tailored to the team you are working with. This step of insights and recommendations would still largely rely on your domain knowledge and communication with stakeholders.
- No XFN Collaborations: Speaking of communication with stakeholders, DS roles today are not just technical roles, but highly collaborative. You need to work with PMs, engineers, designers, and people from all different functions to get clarification on a project, push it forward, and eventually drive business decisions. This is clearly something ChatGPT cannot do for you (well, it can help you draft emails…).
Takeaways
With this all being said, how helpful is ChatGPT for a data scientist? I see four main use cases:
- Quick initial analysis on small datasets (when there is no data privacy concern).
- Help you write code on a specific task or debug. I forget numpy grammar all the time, not to mention various sklearn methods and parameters, so this is definitely a time saver.
- Brainstorm analysis methods and insights. I sometimes use ChatGPT as Google – I give it various scenarios and ask it to suggest solutions with follow-up questions. It could be your perfect brainstorming teammate with abundant knowledge on various topics.
- Polish your analysis report for non-technical audiences. As a non-native speaker, I like to send my draft to ChatGPT and ask it to adjust with a certain tone. Of course, I asked it to edit this post :)
ChatGPT is not ready to replace (good) data scientists yet, but this exercise again reminds me how powerful the tool is and how fast it is evolving. Maybe soon it will overcome many of the limitations above and become an integral part of the data science toolkit. For data scientists, adapting to this new reality and leveraging such tools could be the key to staying ahead in a rapidly changing field.

