
ChatGPT vs. Claude vs. Gemini for Data Analysis (Part 3): Best AI Assistant for Machine Learning
How AI can accelerate your ML projects from feature engineering to model training
Context
Welcome back to the third article of my series, ChatGPT vs. Claude vs. Gemini for Data Analysis! In this series, I aim to compare these AI tools (especially their chatbot interface) across various data science and analytics tasks to help fellow data enthusiasts and professionals choose the best AI assistant for their needs. So far, we’ve explored their performance in writing and optimizing SQL queries and conducting Exploratory Data Analysis — if you haven’t checked those out, be sure to give them a read!
In this article, we’ll shift gears to focus on how these AI tools can assist in Machine Learning projects. Machine learning is a cornerstone of data science. While it is challenging to use LLM models to fully automate the modeling process, these AI tools can still significantly ease the journey through many ML steps.
Steps to Building Machine Learning Models
Unlike SQL or EDA, which can often be largely automated by AI tools today, machine learning is a different beast. In fact, it took me a longer time to write this article because I was debating very hard what I should evaluate the AI tools for, and how to decide the rubrics.
Taking one step back, to evaluate which AI tool truly shines in assisting ML projects, it’s crucial to understand what these tools can — and can’t — do across the key stages of ML model building. Below are the eight essential steps of machine learning:
- Problem Definition: Clearly define the problem you’re trying to solve. This includes understanding the business context, the objectives, and the desired outcomes.
- AI Assistance: Limited. AI tools can help clarify problem statements but often struggle to grasp complex business contexts without human input.
- Data Collection: Gather relevant data from various sources, which might involve accessing databases, APIs, or web scraping.
- AI Assistance: Limited. While chatbots might suggest data sources, the heavy lifting of data collection typically requires manual effort or collaboration with teams.
- Exploratory Data Analysis (EDA): Clean and preprocess data, and analyze its structure, distributions, and relationships. This involves tasks like imputing missing values, generating visualizations, and conducting correlation analysis.
- AI Assistance: Strong. AI tools excel in generating visualizations, providing descriptive statistics, and suggesting insights from the data quickly. You can read more in my last article.
- Feature Engineering: Create new features or transform existing ones to improve the model performance. This includes feature extraction and selection.
- AI Assistance: Strong. AI can suggest new features, explain why certain transformations might be useful, and automate some feature engineering tasks.
- Model Selection: Choose the appropriate machine learning models based on the problem type and data characteristics (e.g., regression, classification, clustering).
- AI Assistance: Moderate. AI can recommend models based on the problem description and data, but you’ll likely need to experiment to find the best fit.
- Model Training and Evaluation: Train models on your data and assess their performance using appropriate metrics. This involves tuning hyperparameters and selecting the best model through cross-validation.
- AI Assistance: Moderate. AI can help with generating training scripts, suggesting evaluation metrics, and tuning hyperparameters, but running the code usually requires external execution and automation.
- Model Deployment: Deploy the model into a production environment where it can make predictions on new data.
- AI Assistance: Limited. AI chatbots can guide you through the deployment process but can’t replace the hands-on work needed.
- Monitoring and Maintenance: Continuously monitor model performance in production, retrain as necessary, and address any drift or degradation over time.
- AI Assistance: Limited. While AI might suggest monitoring tools, ongoing maintenance is a task that extends beyond the capabilities of most AI tools (especially the chatbot interface).
Given this overview, the steps where AI can make the most impact are EDA and feature engineering, with some valuable guidance in model selection, training, and evaluation. Since we’ve already evaluated AI’s performance in EDA, let’s focus on the remaining steps in this article.
Evaluating AI Chatbots in Machine Learning
To put these tools to the test, I used the Online Payment Fraud Detection dataset from Kaggle (CC0: Public Domain license). Fraud detection is a very common machine learning use case and can be approached by supervised learning and unsupervised learning methods. This dataset is too large to fit the file upload limit for all three tools. Therefore, I extracted a 0.5% random sample (3181 rows) with a fraud rate (true positive rate) of 0.2%.
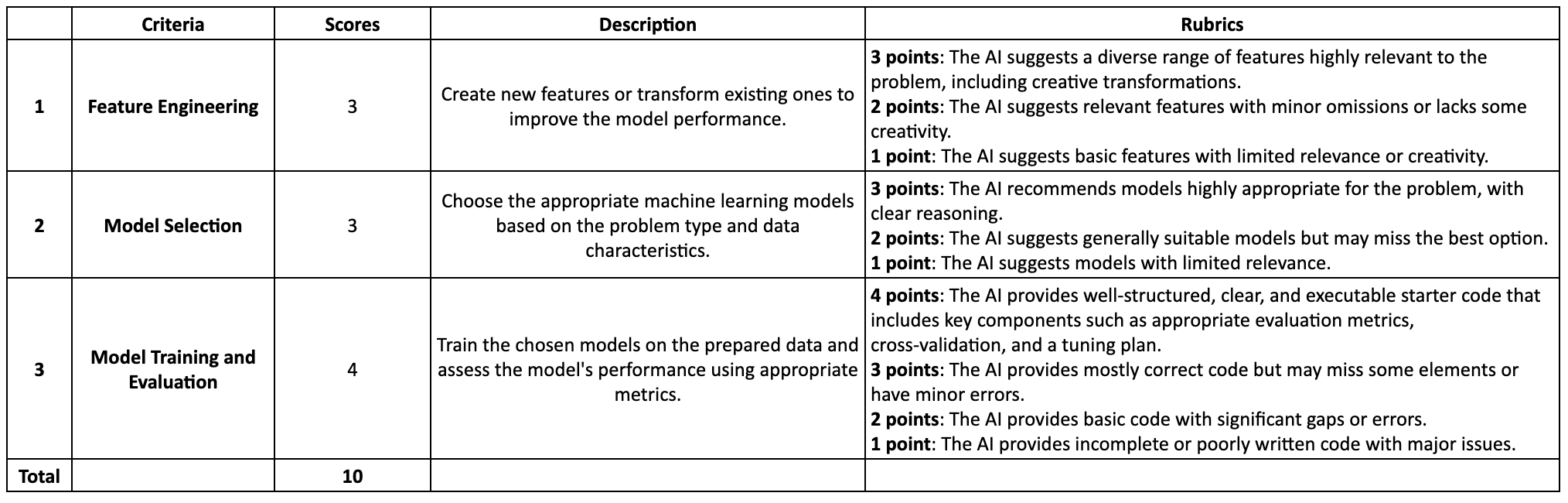
We will evaluate the AI tools following the rubrics below.
1. Feature Engineering
I started by uploading the dataset with column descriptions and tasked the AI tools with suggesting feature engineering techniques.
You are a data scientist working at a bank.
You are provided with this online payment dataset with historical information about fraudulent transactions.
Your goal is to build a machine learning model to detect fraud in online payments.
Below is the detailed column description:
'''
step: represents a unit of time where 1 step equals 1 hour
type: type of online transaction
amount: the amount of the transaction
nameOrig: customer starting the transaction
oldbalanceOrg: balance before the transaction
newbalanceOrig: balance after the transaction
nameDest: recipient of the transaction
oldbalanceDest: initial balance of recipient before the transaction
newbalanceDest: the new balance of recipient after the transaction
isFraud: fraud transaction
'''
Let's do the task step by step. First, please focus on feature engineering.
Can you suggest some feature engineering techniques that could help improve the performance of my model?
Please consider transformations, interactions between features, and any domain-specific features that might be relevant.
Provide a brief explanation for each suggested feature or transformation.
ChatGPT-4o (3/3)
ChatGPT proposed eight categories of features, covering a good variety of feature transformations, interactions, and new feature ideas.
- Feature transformation: ChatGPT suggested doing one-hot-encoding or frequency encoding on the categorical variables. These are the two most common ways to handle categorical variables.
- Feature interaction: ChatGPT recommended creating features like balance differences, relative amounts, and transaction timing based on existing columns to detect transaction anomalies. These are also common features used in real-world fraud detection.
- New features: ChatGPT also proposed creative feature ideals like the unexpected beneficiaries.



I asked it to generate the code to create new features when possible, which worked well without errors.

Claude 3.5 Sonnet (3/3)
Claude came up with 10 categories of features:
- It first categorized features into themes like time-based, transaction amount, balance-related, frequency-based, etc.
- It then covered other feature engineering techniques such as categorical encoding, interactions, aggregation, etc.
- Some features can be calculated from the existing dataset, while others are additional features such as the transaction velocity features.
It was also able to generate Python code that calculated the features correctly.



Gemini Advanced (3/3)
Gemini offered five categories of feature engineering ideas. Many of them are very similar to what ChatGPT and Claude suggested above. The code it generated also performed well.


2. Model Selection
Next, I asked the AI tools to recommend the most suitable model: "Can you recommend the most suitable machine learning models for this task? For each recommended model, provide a brief explanation of why it is appropriate and mention any important considerations for using it effectively".
ChatGPT-4o (3/3)
ChatGPT listed eight model candidates with clear use cases and considerations. This almost covered all the common classification models, along with unsupervised models (KNN and Isolation Forest) for anomaly detection. It also recommended a starting point and next steps.
When I followed up with what specific model it would choose, it answered Gradient Boosting Machines (GBM), specifically XGBoost or LightGBM, given the imbalanced dataset, capability to capture complex patterns, insights into feature importance, and good performance with high efficiency. This aligns with the general practice in the industry pretty well.




Claude 3.5 Sonnet (3/3)
Claude also listed a long list of seven model candidates, with both supervised and unsupervised options. It also listed Ensemble Methods, which is absolutely a good way to improve the model performance. Similar to ChatGPT, it recommended starting with Gradient Boosting Models.




Gemini Advanced (3/3)
Gemini gave five model recommendations, from Logistic Regression to tree-based models and Neural Networks. It further listed four important considerations for imbalanced datasets, which were super important in the context of fraud detection.
I followed up with the question If I don’t have the "isFraud" column, what model will you recommend? to test its knowledge of unsupervised models. It recommended Isolation Forest, which is consistent with ChatGPT and Claude.


3. Model Training and Evaluation
Now let’s come to the last round — model training and evaluation. Here is my prompt: Can you provide the code to train an XGBoost model?
Please ensure that it includes steps like splitting the data into training and testing sets and performing cross-validation. Please also suggest the appropriate evaluation metrics and potential hyperparameters tunning opportunities.
ChatGPT-4o (3.5/4)
ChatGPT delivered an accurate and well-structured code script, covering all aspects from model training, evaluation, and cross-validation, to hyperparameter tuning. The code ran successfully without any errors. It also explained the evaluation metrics choices and provided hyperparameter tuning suggestions with good reasoning.
Everything looks good up to this point. However, I still deducted 0.5 points because it did not cover any treatment for the imbalanced dataset such as upsampling, SMOTE, or adjusting relevant parameters in XGBoost (e.g. scale_pos_weight). Our dataset only has a 0.2% true positive rate, therefore it is critical to keep that into consideration when training the models. This highlights a significant drawback of relying solely on AI tools for machine learning — they can generate functional code but might overlook critical steps, such as handling imbalanced datasets, due to the complexity of real-world data.

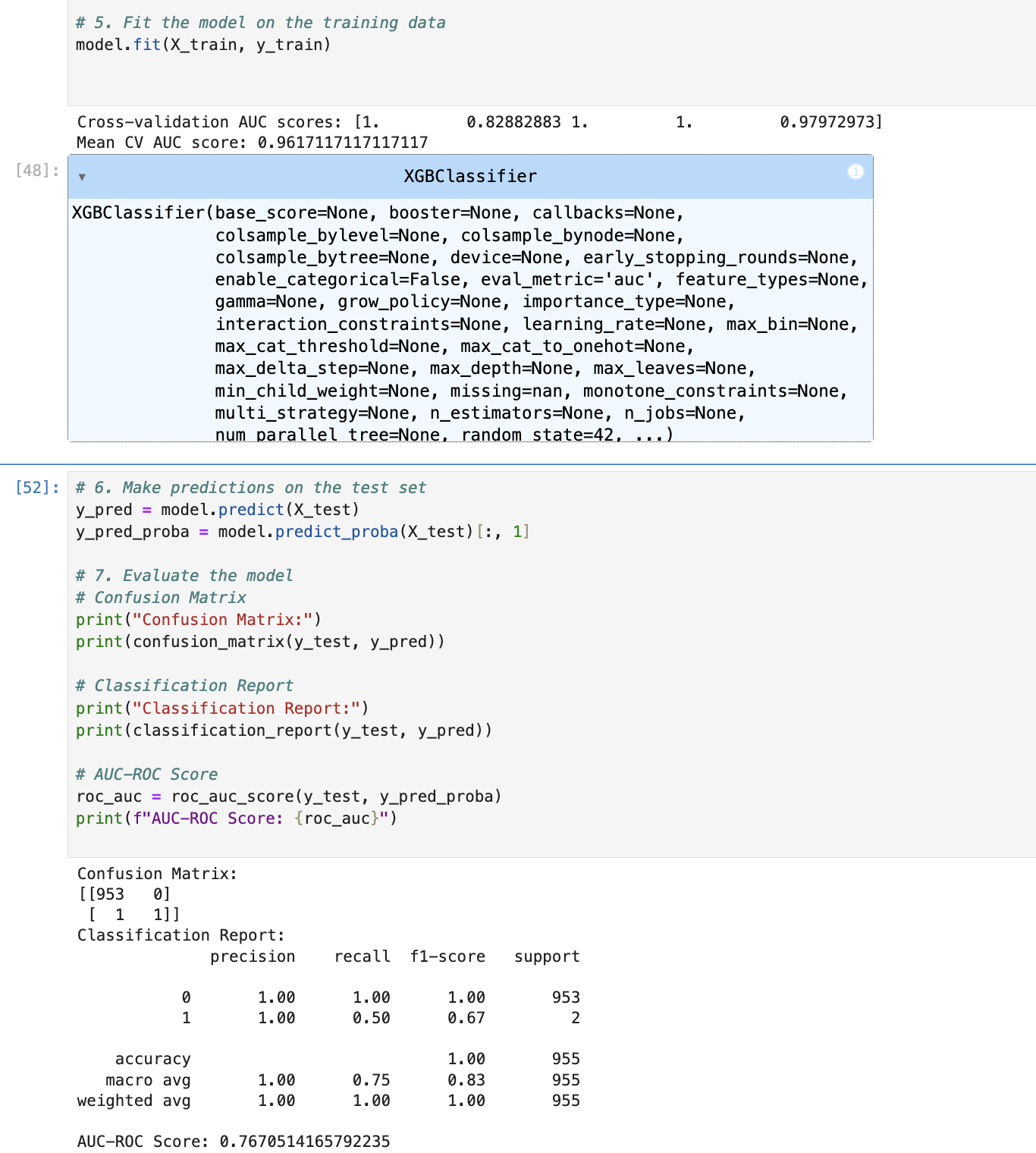
Claude 3.5 Sonnet (3/4)
Claude also provided comprehensive code that covered all the essential steps from training and evaluation to hyperparameter tuning. It included a step to handle class imbalance using SMOTE. However, when I tried to run the code locally, I encountered an error with SMOTE due to missing values in some columns. Its hyperparameter tuning code also had a syntax error in the fit method.
Therefore, I gave it 3 out of 4 points.


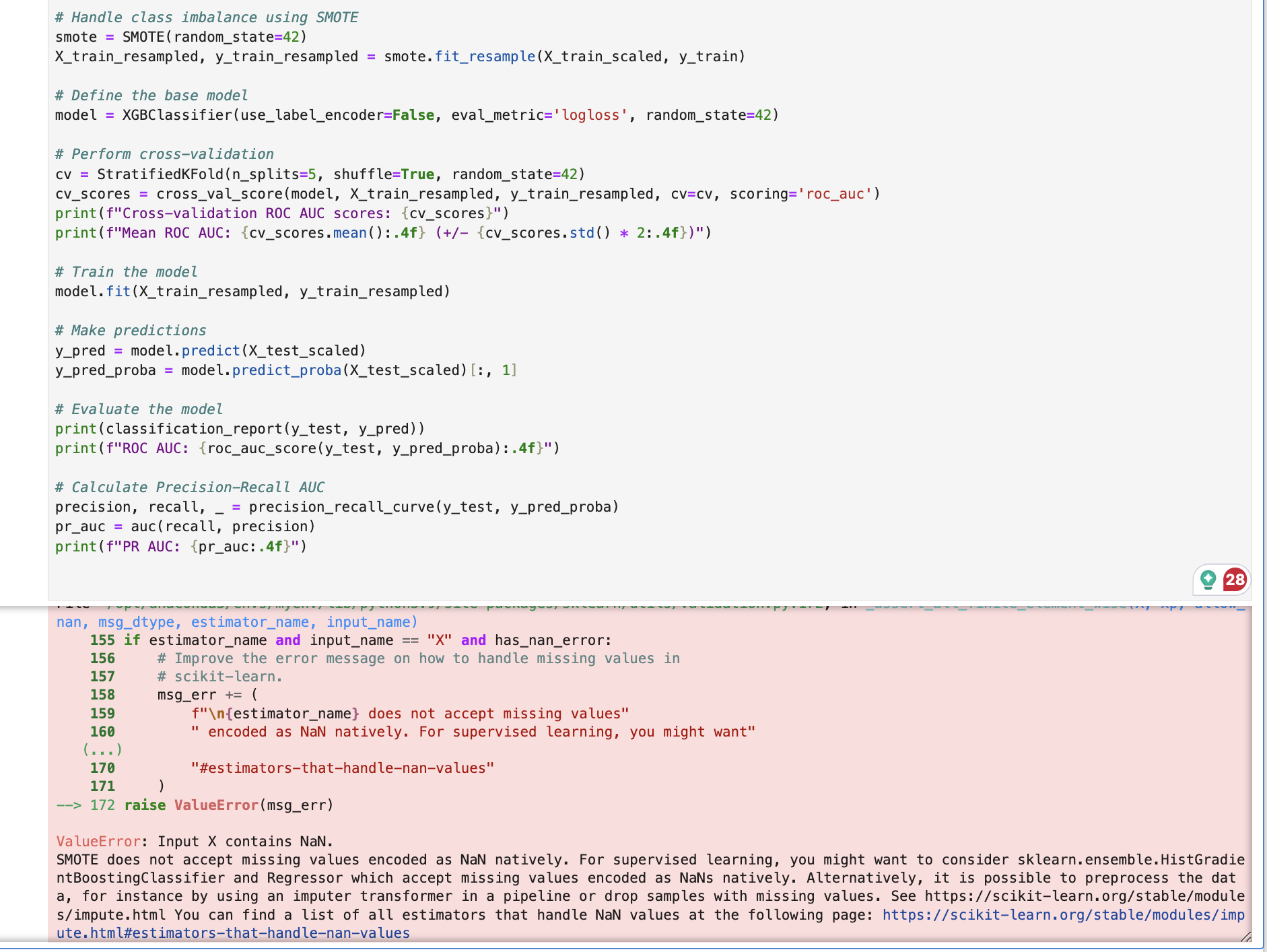
Another very important issue I want to raise is that Claude created frequency-based features (e.g. transaction_count_per_customer, unique_recipients_per_customer) in its earlier steps. However, these features were calculated based on the complete dataset before the training and testing split, leading to potential data leakage. When I brought up this question with Claude, it was fast to recognize the issue and proposed solutions like time-based splits. However, this is another great example of nuances LLM could miss easily without domain expertise. Though I did not deduct any points for this — It felt a bit unfair to punish Claude for issues that ChatGPT and Gemini did not run into simply because they did not create these features.

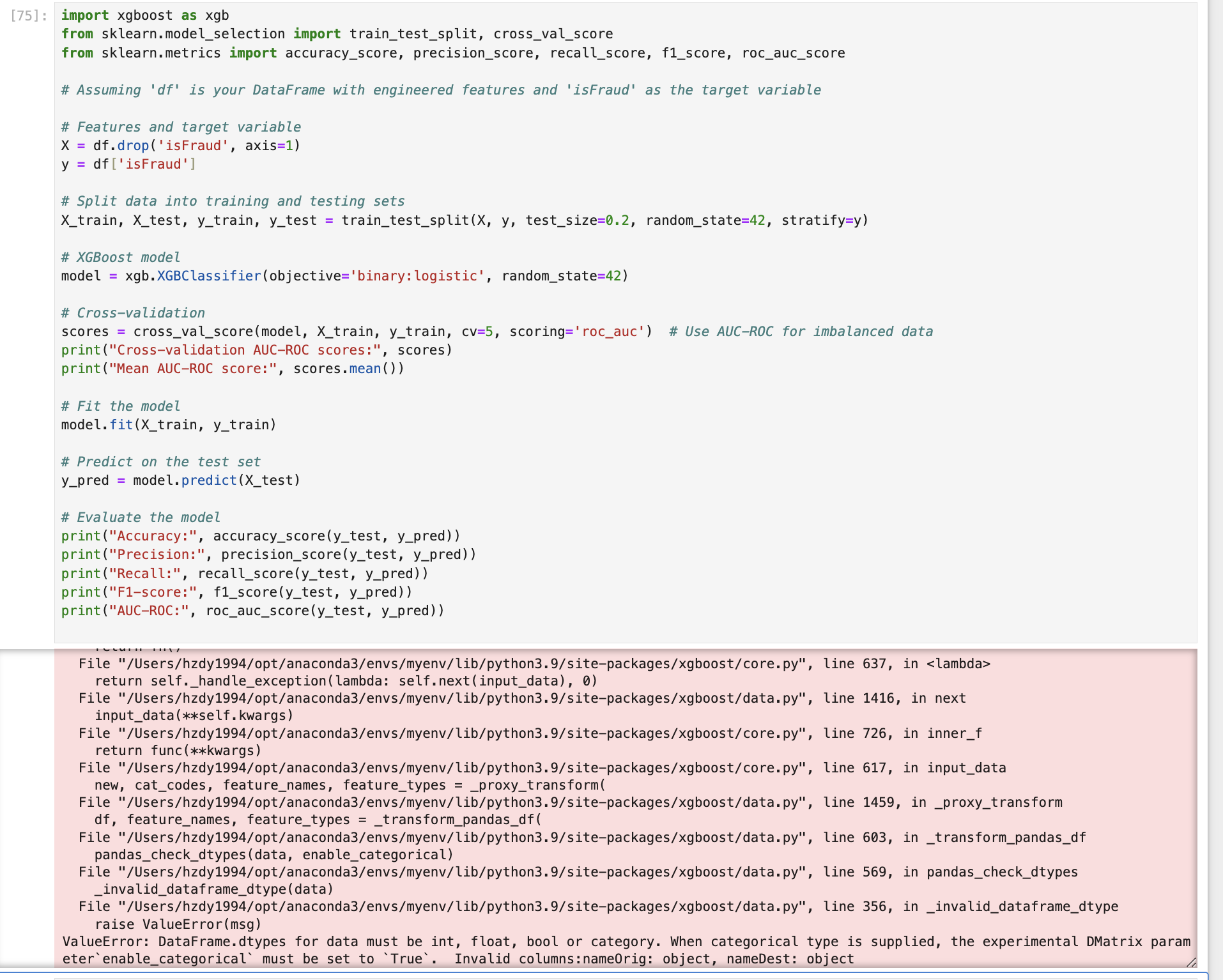
Gemini Advanced (2/4)
Gemini also chose appropriate evaluation metrics with good reasoning. The code it provided covered basic model training, cross-validation, and evaluation. However, it did not exclude categorical variables from the data frame, leading to an error when running model training locally. When I asked it to generate code for hyperparameter tuning, it first failed with some error message in the chatbot interface, then provided code with clear syntax errors… (Unfortunately, Gemini is the least stable AI tool out of the three throughout my tests.)
Therefore, I gave it 2 out of 4 points.


Final Results
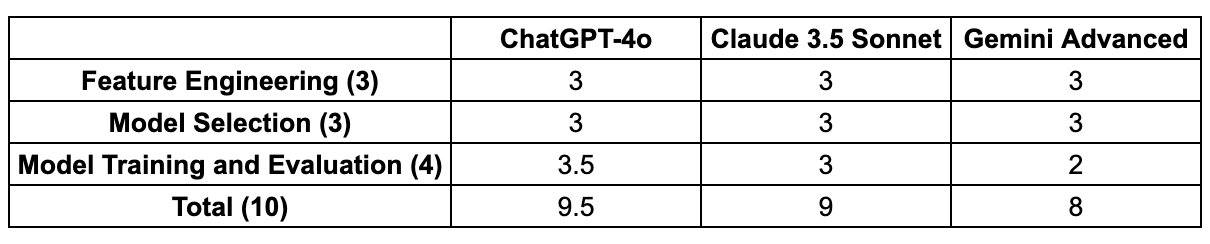
In this round of ML assistant competition, the winner goes to …🥁 ChatGPT-4o!
This is primarily due to its high accuracy in code generation during model training and evaluation. Meanwhile, all three tools demonstrated strong capabilities in feature engineering and model selection.
That being said, AI tools still have many limitations in assisting with machine learning:
- They excel at suggesting new features, recommending models, and generating code, but integrating these steps into a seamless process remains a challenge.
- Moreover, human expertise is still crucial today in machine learning. If you are not aware of the necessity of handling an imbalanced dataset, you will miss that step by simply following ChatGPT’s script. Similarly, Claude’s data leakage issue due to its inappropriate feature engineering setup is another perfect example of where human expertise remains indispensable.
In summary, AI tools, particularly ChatGPT-4o, make excellent brainstorming partners for generating new features, exploring various model options, and crafting evaluation strategies. However, human expertise is still strongly required to build robust and effective machine learning models.

