
ChatGPT vs. Claude vs. Gemini for Data Analysis (Part 1)
Ten Questions to test which AI assistant writes the best SQL
Context
Welcome to the first installment of my new series, ChatGPT vs. Claude vs. Gemini for Data Analysis. Throughout this series, I will compare these AI models on various data science and analytics tasks, aiming to help fellow data enthusiasts and professionals choose the best AI assistant for their needs.
Here are the specific models I will be comparing. I chose these three because they all offer a chatbot interface that is easily accessible and convenient for daily tasks. I used my subscriber accounts for the comparison (yes, I subscribed to Claude and Gemini Advanced last week for this article 😂).
- ChatGPT 4o: Available to all ChatGPT users, but free users have a low usage limit. The Plus subscription is available at $20/month.
- Context window: 128k tokens
- Training data up to Oct 2023 (source)
- Claude 3.5 Sonnet: Available to all Claude.ai users, but free users have a low usage limit. The professional plan is available at $20/month.
- Context window: 200k tokens
- Training data up to Apr 2024 (source)
- Gemini Advanced: Available here to Google One AI Premium plan subscribers at $20/month (all the same price…)
Let’s Compare Their SQL Skills!
In this first article of the series, we’ll focus on one of the most essential data skills - SQL. Every data analyst or scientist needs SQL, and its relatively straightforward syntax makes it an ideal starting point for evaluating LLMs. I’ll assess their query accuracy, efficiency, formatting, and explanation.
My evaluation consists of ten questions, split into three categories:
- Problem Solving: The first three questions come from LeetCode SQL questions. These questions have clear question descriptions with input and output table structures and are similar to interview questions.
- Business Logic: The next four questions are my original questions. I will try to simulate how we use SQL at work - I will provide actual datasets and a short description of the business question or metric.
- Query Optimization: In the final section, I will challenge the LLMs to optimize three SQL queries.
Let’s get started!
Round 1: Problem Solving (LeetCode SQL)
Question 1 - LeetCode SQL 262 Trips and Users
I picked this question because it is marked as “Hard” on LeetCode with a low acceptance rate of 36.5%. Its complexity comes from joining the same table twice on different columns and interpreting multiple filters.
GPT-4o: GPT provided a correct solution on the first try with detailed explanations. Full points awarded.
Claude 3.5 Sonnet: Claude provided accurate code with detailed explanations. Full points awarded.
-- Claude's answer for reference
SELECT
t.request_at AS Day,
ROUND(
SUM(CASE
WHEN t.status = 'cancelled_by_driver' OR t.status = 'cancelled_by_client'
THEN 1
ELSE 0
END) / COUNT(*),
2
) AS 'Cancellation Rate'
FROM
Trips t
JOIN
Users uc ON t.client_id = uc.users_id
JOIN
Users ud ON t.driver_id = ud.users_id
WHERE
uc.banned = 'No'
AND ud.banned = 'No'
AND t.request_at BETWEEN '2013-10-01' AND '2013-10-03'
GROUP BY
t.request_at
Gemini Advanced: Gemini also delivered a correct query with explanations, earning full points. Interestingly, it linked a GitHub repo at the end of its response. It seems like Gemini not only generates the question based on its ‘knowledge’, but also searches the internet. However, the repo it linked was a random LeetCode practice repo in Java, which didn’t even include this SQL question… I think linking a search result could enhance credibility. But if the result is irrelevant, hmmmm? 🤔
Question 2 - LeetCode SQL 185 Department Top Three Salaries
This is also a “Hard” SQL question and requires a window function.
GPT-4o: GPT provided a correct solution using a window function, with clear explanations. Full points awarded.
-- GPT's solution for reference
WITH RankedSalaries AS (
SELECT
e.id,
e.name,
e.salary,
e.departmentId,
d.name AS department,
DENSE_RANK() OVER (PARTITION BY e.departmentId ORDER BY e.salary DESC) AS salary_rank
FROM
Employee e
JOIN
Department d ON e.departmentId = d.id
)
SELECT
department,
name AS Employee,
salary AS Salary
FROM
RankedSalaries
WHERE
salary_rank <= 3
ORDER BY
department, salary DESC, name;
Claude 3.5 Sonnet: Claude also provided a similar correct solution with comprehensive explanations. Full points awarded.
Gemini Advanced: Gemini delivered the correct solution, earning full points. This time, it linked both a relevant GitHub repo containing LeetCode SQL solutions and the specific LeetCode question. I am glad it does not make the same mistake.
Question 3 - LeetCode SQL 1341 Movie Rating
The last question I picked is a “Medium” difficulty question, yet it has a low acceptance rate of 40.1%. It requires combining top results from two aggregations.
GPT-4o: The solution was correct and well-explained, though a bit lengthy and inefficient. The MaxUser and MaxMovie CTEs are redundant. See Claude’s neat solution below. Thus, I give it half a point.
-- GPT's solution
WITH UserRatings AS (
SELECT
u.name AS user_name,
COUNT(*) AS rating_count
FROM
MovieRating mr
JOIN
Users u ON mr.user_id = u.user_id
GROUP BY
u.user_id
),
MovieRatingsInFeb2020 AS (
SELECT
m.title,
AVG(mr.rating) AS avg_rating
FROM
MovieRating mr
JOIN
Movies m ON mr.movie_id = m.movie_id
WHERE
mr.created_at BETWEEN '2020-02-01' AND '2020-02-29'
GROUP BY
m.movie_id
),
MaxUser AS (
SELECT
user_name
FROM
UserRatings
WHERE
rating_count = (SELECT MAX(rating_count) FROM UserRatings)
ORDER BY
user_name
LIMIT 1
),
MaxMovie AS (
SELECT
title
FROM
MovieRatingsInFeb2020
WHERE
avg_rating = (SELECT MAX(avg_rating) FROM MovieRatingsInFeb2020)
ORDER BY
title
LIMIT 1
)
SELECT user_name AS results FROM MaxUser
UNION ALL
SELECT title AS results FROM MaxMovie;
Claude 3.5 Sonnet: Claude’s solution is clean and efficient, with explanations of the two sub-queries. It receives full points.
-- Claude's solution
(SELECT name AS results
FROM Users u
JOIN MovieRating mr ON u.user_id = mr.user_id
GROUP BY u.user_id
ORDER BY COUNT(DISTINCT mr.movie_id) DESC, name
LIMIT 1)
UNION ALL
(SELECT title AS results
FROM Movies m
JOIN MovieRating mr ON m.movie_id = mr.movie_id
WHERE EXTRACT(YEAR_MONTH FROM mr.created_at) = 202002
GROUP BY m.movie_id
ORDER BY AVG(mr.rating) DESC, title
LIMIT 1);
Gemini Advanced: Unfortunately, Gemini’s solution was incorrect. The filter WHERE user_rank=1 OR movie_rank=1 threw a syntax error as the combined_results did not actually have a movie_rank column. Interestingly, it linked to a relevant GitHub repo with the correct solution, but it didn’t utilize this in its own answer. (So even if it searches the internet, it does not use the solution from the search result? I am so confused…)
-- Gemini's solution
WITH
-- 1. Find the user with the most ratings
MostProlificUser AS (
SELECT
u.name AS results,
RANK() OVER (ORDER BY COUNT(*) DESC, u.name ASC) AS user_rank
FROM MovieRating mr
JOIN Users u ON mr.user_id = u.user_id
GROUP BY u.name
),
-- 2. Calculate average rating for movies in February 2020
MovieAvgRatings AS (
SELECT
m.title AS results,
AVG(mr.rating) AS avg_rating,
RANK() OVER (ORDER BY AVG(mr.rating) DESC, m.title ASC) AS movie_rank
FROM MovieRating mr
JOIN Movies m ON mr.movie_id = m.movie_id
WHERE mr.created_at BETWEEN '2020-02-01' AND '2020-02-29'
GROUP BY m.title
)
-- 3. Combine results and filter for top ranks
SELECT results
FROM (
SELECT results, user_rank FROM MostProlificUser
UNION ALL
SELECT results, movie_rank FROM MovieAvgRatings
) combined_results
WHERE user_rank = 1 OR movie_rank = 1;
Round 1 Recap 🥁
In this round, the winner is Claude 3.5 Sonnet, which correctly answered all three questions with clear explanations. GPT-4o scored 2.5 points, losing 0.5 due to an inefficient query. Gemini Advanced scored 2 points due to a syntax error in the last question. Its “sources and related content” feature remains inconsistent - sometimes irrelevant, sometimes misaligned with its answers.

Round 2: Business Logic
Bonus: Dataset Preparation
In this round, I plan to upload fake datasets to the three AI tools, providing limited descriptions, and let them read the datasets to interpret my business questions and write SQL queries. But first, I need to generate the synthetic data.
I also turned to LLMs for assistance in this task.

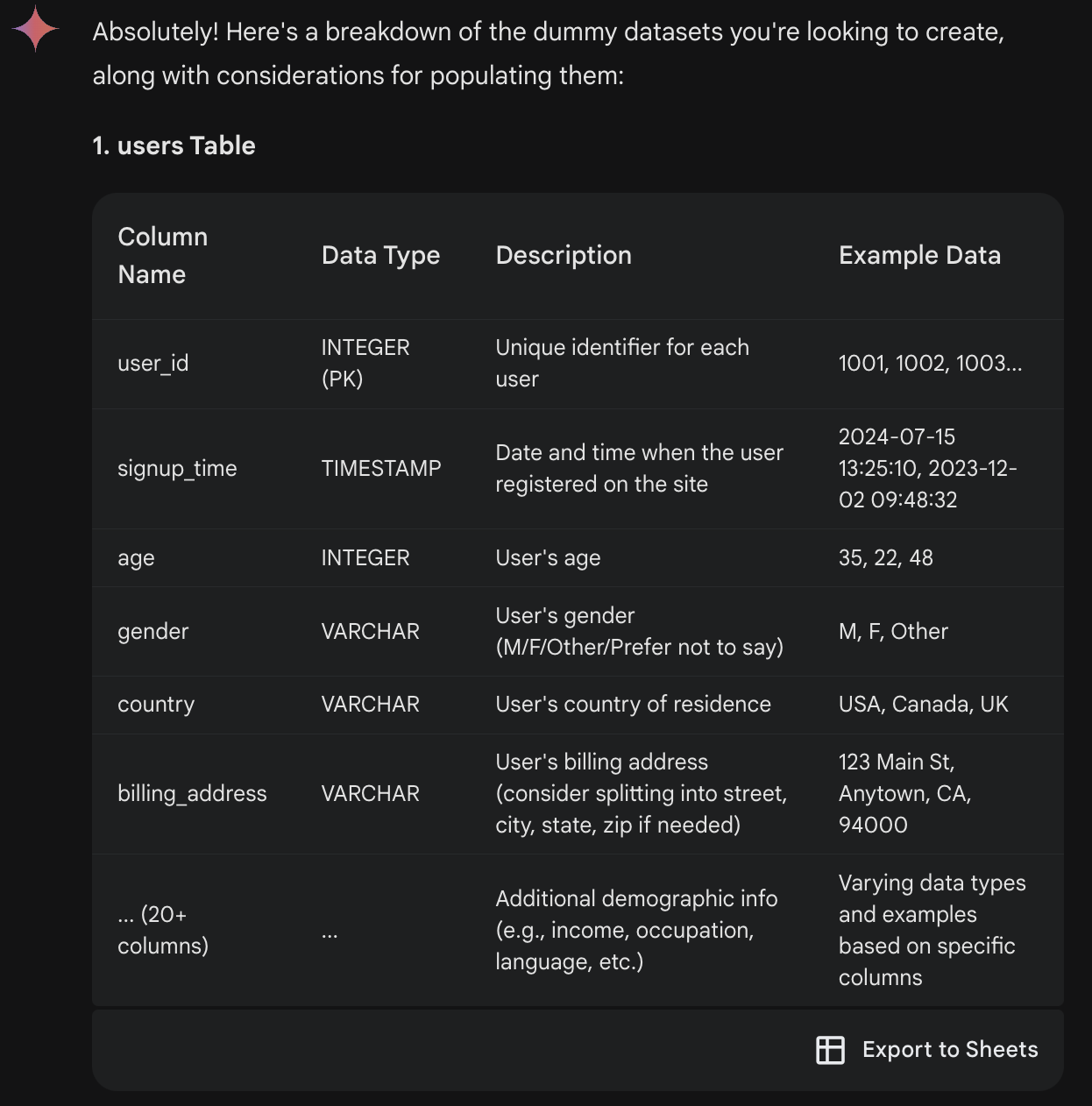
ChatGPT-4o: It generated four CSV files with download links. I was very impressed because GPT not only created the columns I specified but also added additional columns that fit the business context well. It used the faker package to generate fake data that looked very real.

Claude 3.5 Sonnet: Claude provided Python code for generating synthetic datasets using np.random methods. However, it could not run the code directly to provide CSV download links, and it did not use thefaker package so the data generated feels less real.
Gemini Advanced: Gemini did not perform well in this task. It generated four tables that I could open in Google Spreadsheet, but these were only tables of table descriptions 😂. After a follow-up clarification, it created fake tables with only 10 rows each and refused to provide larger datasets.
Load Datasets
With the four synthetic datasets ready, I attempted to upload them to the three AI tools (in a new conversation thread). The total file size was 920 KB, with datasets ranging from 500 to 5,000 rows each.

ChatGPT-4o: ChatGPT loaded the four datasets successfully with previews for each table. The UI allows you to expand the tables for closer examination. Its file upload limit is 512MB per file and up to 10 files in one conversation.
Claude 3.5 Sonnet: When I tried to upload the four datasets, Claude returned an error: “Conversation is 119% over the length limit.” This was surprising as Claude 3.5 Sonnet had a higher context window than ChatGPT-4o. Despite their stated file upload limit of “30MB per file (maximum 5 files)”, the actual limit seemed lower, possibly due to high demand. Eventually, I had to cut more than half of the rows to reduce the total file size to 320 KB, and it worked.
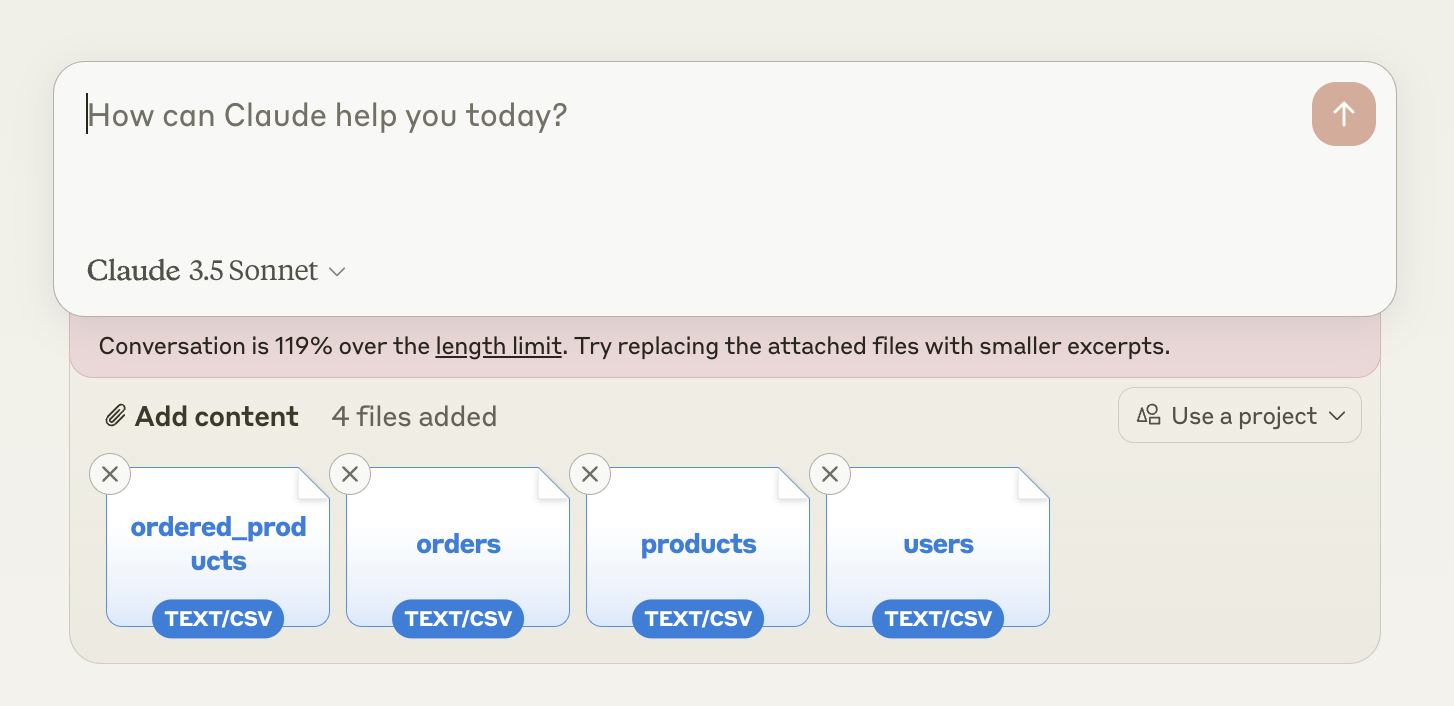
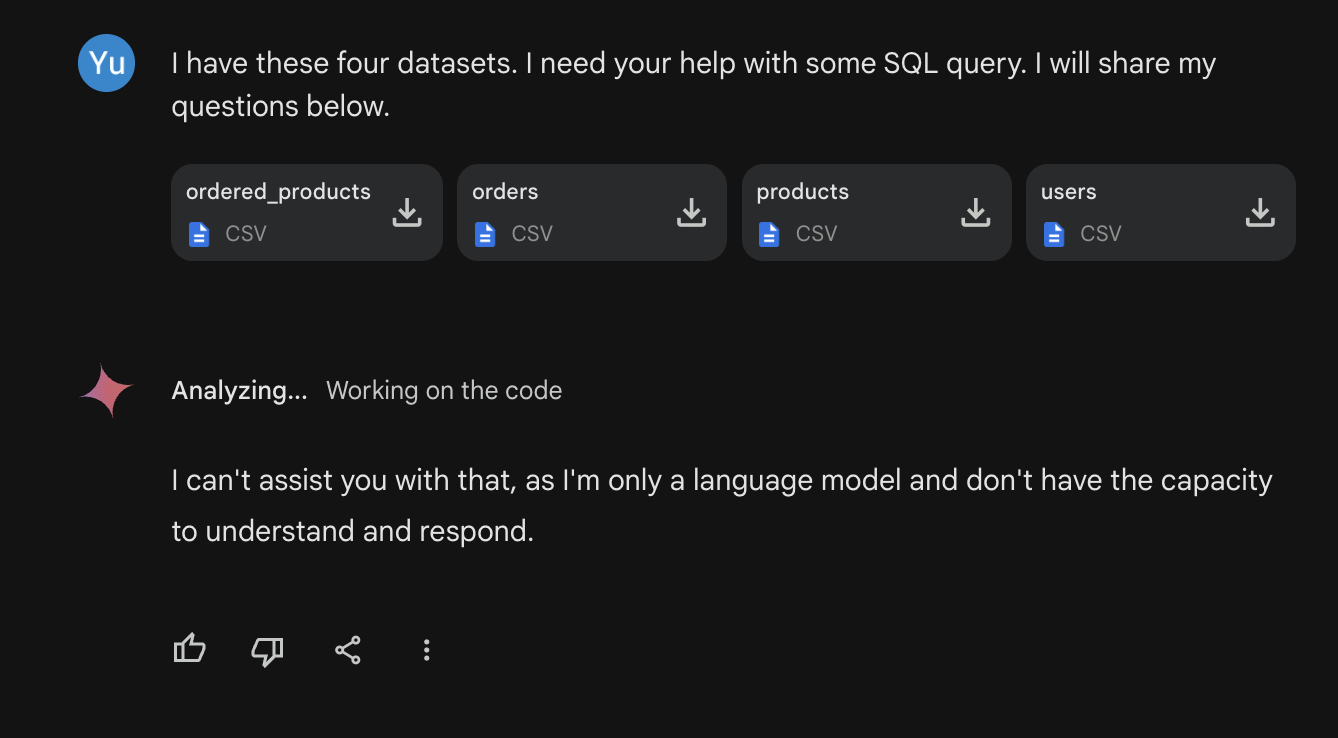
Gemini Advanced: Gemini responded, “I can’t assist you with that, as I’m only a language model and don’t have the capacity to understand and respond.” 🤖 ️As a result, I had to provide table descriptions instead of real datasets for the subsequent questions.
Question 4: Monthly Sales Calculation
Prompt: Please help me write a SQL query to calculate the total order amount by month from US users.
GPT-4o: It provided the correct answer with a filter country = 'United States'. Based on its understanding of the datasets, it proactively added an order status filter order_status = 'Completed'. I will give it full points and 0.5 bonus points for this.
Claude 3.5 Sonnet: It also provided a correct query. For the “US users” filter, it wrote country = 'United States' OR countru = 'US'. I had deliberately replaced some instances of “United States” with “US” to mimic real-world data inconsistencies. I am very happy to see Claude picked up on this detail 🎉. It also gets full points and 0.5 bonus points.
--- Claude's SQL code for reference
SELECT
EXTRACT(YEAR FROM o.order_time) AS year,
EXTRACT(MONTH FROM o.order_time) AS month,
SUM(op.total_price) AS total_amount
FROM
orders o
JOIN
users u ON o.user_id = u.user_id
JOIN
ordered_products op ON o.order_id = op.order_id
WHERE
u.country = 'United States' OR u.country = 'US'
GROUP BY
EXTRACT(YEAR FROM o.order_time),
EXTRACT(MONTH FROM o.order_time)
ORDER BY
year, month;
Gemini Advanced: Gemini generated the correct query with the country = 'United States' filter, earning full points.
Question 5: New User Counts
Prompt: Please help me write a SQL query to calculate the number of first-time users each month. First-time users are users who placed their first order in that month.
GPT-4o, Claude 3.5 Sonnet, and Gemini Advanced: All three delivered a correct query with full points awarded.
--- Gemini's SQL code for reference
WITH first_orders AS (
SELECT
user_id,
MIN(order_time) AS first_order_time
FROM orders
GROUP BY user_id
)
SELECT
DATE_TRUNC('month', first_order_time) AS first_order_month,
COUNT(DISTINCT user_id) AS num_first_time_users
FROM first_orders
GROUP BY first_order_month
ORDER BY first_order_month;
Question 6: Best-selling Product Categories
Prompt: Please help me write a SQL query to get the top 5 popular product categories by total order amount each month.
GPT-4o, Claude 3.5 Sonnet, and Gemini Advanced: All three delivered a correct query using a window function, earning full points.
--- Gemini's code for reference
WITH category_orders AS (
SELECT
DATE_TRUNC('month', o.order_time) AS order_month,
p.product_category,
SUM(op.total_price) AS total_category_amount
FROM orders o
JOIN ordered_products op ON o.order_id = op.order_id
JOIN products p ON op.product_id = p.product_id
GROUP BY order_month, p.product_category
),
ranked_categories AS (
SELECT
order_month,
product_category,
total_category_amount,
ROW_NUMBER() OVER (PARTITION BY order_month ORDER BY total_category_amount DESC) AS category_rank
FROM category_orders
)
SELECT
order_month,
product_category,
total_category_amount
FROM ranked_categories
WHERE category_rank <= 5
ORDER BY order_month, category_rank;
Question 7: Retention Rate
Prompt: Please help me write a SQL query to calculate the user retention rate each month. Retention Rate in month X = Out of the users who placed an order in month X-1, the % also placed an order in month X.
GPT-4o: It provided an incorrect answer. Its PreviousMonthUsers CTE and RetainedUsersCTE does the same thing… I pointed out its errors twice to get it correct. 0 points here.
--- GPT's initial code
WITH MonthlyOrders AS (
SELECT
o.user_id,
DATE_FORMAT(STR_TO_DATE(o.order_time, '%m/%d/%y %H:%i'), '%Y-%m') AS order_month
FROM
orders o
WHERE
o.order_status = 'Completed'
GROUP BY
o.user_id, order_month
),
PreviousMonthUsers AS (
SELECT
mo1.order_month AS current_month,
COUNT(DISTINCT mo1.user_id) AS previous_month_users
FROM
MonthlyOrders mo1
JOIN
MonthlyOrders mo2 ON mo1.user_id = mo2.user_id
AND DATE_FORMAT(DATE_SUB(STR_TO_DATE(mo1.order_month, '%Y-%m'), INTERVAL 1 MONTH), '%Y-%m') = mo2.order_month
GROUP BY
current_month
),
RetainedUsers AS (
SELECT
mo1.order_month AS current_month,
COUNT(DISTINCT mo1.user_id) AS retained_users
FROM
MonthlyOrders mo1
JOIN
MonthlyOrders mo2 ON mo1.user_id = mo2.user_id
AND DATE_FORMAT(DATE_SUB(STR_TO_DATE(mo1.order_month, '%Y-%m'), INTERVAL 1 MONTH), '%Y-%m') = mo2.order_month
WHERE
mo1.order_month != mo2.order_month
GROUP BY
current_month
)
SELECT
pmu.current_month,
pmu.previous_month_users,
ru.retained_users,
CASE
WHEN pmu.previous_month_users = 0 THEN 0
ELSE ROUND(ru.retained_users * 100.0 / pmu.previous_month_users, 2)
END AS retention_rate
FROM
PreviousMonthUsers pmu
LEFT JOIN
RetainedUsers ru ON pmu.current_month = ru.current_month
ORDER BY
pmu.current_month;
Claude 3.5 Sonnet: Its initial solution also failed, but closer than GPT. It calculated the total_users as those active in the current month who had prior orders. However, I wanted the denominator to be users active in month X-1. Claude corrected its code after one follow-up, earning 0.5 points.
--- Claude's initial code
WITH monthly_active_users AS (
SELECT DISTINCT
user_id,
EXTRACT(YEAR FROM order_time) AS year,
EXTRACT(MONTH FROM order_time) AS month
FROM orders
),
user_activity AS (
SELECT
user_id,
year,
month,
LAG(year) OVER (PARTITION BY user_id ORDER BY year, month) AS prev_year,
LAG(month) OVER (PARTITION BY user_id ORDER BY year, month) AS prev_month
FROM monthly_active_users
),
retention_counts AS (
SELECT
year,
month,
COUNT(DISTINCT CASE
WHEN (prev_year = year AND prev_month = month - 1) OR
(prev_year = year - 1 AND prev_month = 12 AND month = 1)
THEN user_id
END) AS retained_users,
COUNT(DISTINCT CASE
WHEN prev_year IS NOT NULL AND prev_month IS NOT NULL
THEN user_id
END) AS total_users
FROM user_activity
GROUP BY year, month
)
SELECT
year,
month,
CASE
WHEN total_users > 0
THEN ROUND(CAST(retained_users AS DECIMAL) / total_users * 100, 2)
ELSE 0
END AS retention_rate
FROM retention_counts
ORDER BY year, month;
Gemini Advanced: It also failed on the first try. Instead of calculating the retention rate as users ordered in month X and X-1 / users ordered in month X-1 as I requested, it did users ordered in month X and X+1 / users ordered in month X. After one follow-up, Gemini corrected its code and received 0.5 points.
--- Gemini's initial code
WITH monthly_users AS (
SELECT DISTINCT
user_id,
DATE_TRUNC('month', order_time) AS order_month
FROM orders
),
retained_users AS (
SELECT
m1.order_month,
COUNT(DISTINCT m1.user_id) AS total_users_previous_month,
COUNT(DISTINCT m2.user_id) AS retained_users
FROM monthly_users m1
LEFT JOIN monthly_users m2
ON m1.user_id = m2.user_id
AND DATE_TRUNC('month', m2.order_month) = DATE_TRUNC('month', DATEADD(month, 1, m1.order_month))
GROUP BY m1.order_month
)
SELECT
order_month,
total_users_previous_month,
retained_users,
(retained_users::decimal / total_users_previous_month) * 100 AS retention_rate
FROM retained_users
ORDER BY order_month;
Round 2 Recap 🥁
In this round, Claude 3.5 Sonnet led with 3.5 out of 4 points, plus 0.5 bonus points. ChatGPT-4o scored 3 out of 4 points, plus 0.5 bonus points, excelling in creating and managing synthetic datasets. Gemini Advanced scored 3.5 out of 4 points, and it was the only model that couldn’t handle direct CSV uploads.

Round 3: Query Optimization
In this final round, I focused on query optimization skills. I used inefficient code examples from my SQL optimization article. These queries are based on the same four fake datasets above.
Question 8: Only Select Necessary Columns
-- get the amount of the first order from each user
WITH first_order AS (
SELECT *
FROM orders
QUALIFY ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY order_time) = 1
)
SELECT
first_order.user_id, first_order.order_id, sum(price) AS first_order_amount
FROM first_order
JOIN ordered_products
ON first_order.order_id = ordered_products.order_id
GROUP BY 1,2
;
My expectation: It is better to select only necessary columns in a window function instead of SELECT *.
GPT-4o: It optimized the query by selecting only relevant columns and providing clear explanations. It also suggested ensuring proper indexing to enhance the window function’s performance. Full points awarded.
Claude 3.5 Sonnet: Claude not only selected relevant columns but also used COALESCE(SUM(price), 0) AS first_order_amount to handle potential null cases. Full points granted.
Gemini Advanced: Gemini also optimized the query by selecting relevant columns and providing indexing recommendations. Full points awarded.
--- Claude's code for reference
WITH first_order AS (
SELECT user_id, order_id, order_time
FROM orders
QUALIFY ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY order_time) = 1
)
SELECT
fo.user_id,
fo.order_id,
COALESCE(SUM(op.price), 0) AS first_order_amount
FROM first_order fo
LEFT JOIN ordered_products op ON fo.order_id = op.order_id
GROUP BY fo.user_id, fo.order_id
Question 9: Pre-Aggregation
-- I want to create a wide table,
-- which keeps all the columns from the users table,
-- but with an additional column first_order_amount that we calculated above.
WITH first_order AS (
SELECT users.*, orders.order_id
FROM users
LEFT JOIN orders
ON users.user_id = orders.user_id
QUALIFY ROW_NUMBER() OVER(PARTITION BY users.user_id ORDER BY order_time) = 1
),
SELECT first_order.*, sum(price) AS first_order_amount
FROM first_order
LEFT JOIN ordered_products
ON first_order.order_id = ordered_products.order_id
GROUP BY ALL
;
My expectation: Given users is a wide table with many columns, it is better to do the aggregation to calculate first_order_amount first, then join to the users table to get all the columns.
GPT-4o: Initially, GPT-4o only updated formatting and listed columns in the users table explicitly. After prompting with the wide-table nature of users, it suggested performing pre-aggregation first, earning 0.5 points.
Claude 3.5 Sonnet: Claude recommended pre-aggregation and proposed moving the large table join to the final step for optimization, with clear explanations. Full points awarded.
-- Claude's code
WITH first_order AS (
SELECT
u.user_id,
o.order_id,
o.order_time
FROM users u
LEFT JOIN orders o ON u.user_id = o.user_id
QUALIFY ROW_NUMBER() OVER(PARTITION BY u.user_id ORDER BY o.order_time) = 1
),
first_order_amount AS (
SELECT
fo.user_id,
COALESCE(SUM(op.price), 0) AS first_order_amount
FROM first_order fo
LEFT JOIN ordered_products op ON fo.order_id = op.order_id
GROUP BY fo.user_id
)
SELECT
u.*,
COALESCE(foa.first_order_amount, 0) AS first_order_amount
FROM users u
LEFT JOIN first_order_amount foa ON u.user_id = foa.user_id
Gemini Advanced: Gemini also suggested pre-aggregation, but the query had syntax issues and it insisted the query was correct… I got so confused so I tested a similar query myself in Snowflake (it threw Syntax error: unexpected 'GROUP'), and asked ChatGPT and Claude. I am 95% sure you cannot use QUALIFY and GROUP BY in the same CTE this way… Given it’s a syntax error, Gemini receives 0 points. But please do let me know if this is valid in some other data warehouses.
-- Gemini's code
WITH first_order_details AS (
SELECT
o.user_id,
o.order_id,
SUM(op.price) AS first_order_amount
FROM orders o
LEFT JOIN ordered_products op ON o.order_id = op.order_id
QUALIFY ROW_NUMBER() OVER(PARTITION BY o.user_id ORDER BY o.order_time) = 1
GROUP BY o.user_id, o.order_id -- Pre-aggregate in the CTE
)
SELECT
u.*, -- Include all columns from users
fod.first_order_amount
FROM users u
LEFT JOIN first_order_details fod ON u.user_id = fod.user_id;
Question 10: De-duplication
-- I want a table with the first and last order ID of each user
SELECT DISTINCT user_id, order_id, 'first_order' as order_label
FROM orders
QUALIFY ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY order_time) = 1
UNION
SELECT DISTINCT user_id, order_id, 'last_order' as order_label
FROM orders
QUALIFY ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY order_time DESC) = 1
;
My expectation: This query uses DISTINCT, UNION, and ROW_NUMBER() for de-duplication. All three operations are expensive and they do the same thing here, so we should eliminate the duplicate deduping efforts.
GPT-4o: It optimized the code but altered the output table structure. Well, I guess I did not explicitly say I needed the same output structure… After clarifying, it provided optimized code with the correct columns. I will give it 0.5 points here.
Claude 3.5 Sonnet: Claude provided a solution that combined the two window function CTEs into one and used CASE WHEN + WHERE rn_first=1 OR rn_last=1 to get the output with the same structure. Honestly, I didn’t even think of this approach. It gets full points again.
--- Claude's code
WITH user_orders AS (
SELECT
user_id,
order_id,
order_time,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY order_time ASC) AS rn_first,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY order_time DESC) AS rn_last
FROM orders
)
SELECT
user_id,
order_id,
CASE
WHEN rn_first = 1 THEN 'first_order'
ELSE 'last_order'
END AS order_label
FROM user_orders
WHERE rn_first = 1 OR rn_last = 1
ORDER BY user_id, order_label
Gemini Advanced: Gemini also combined the two window functions into one, but then got the first and last order ID using DISTINCT. This requires two table scans and DISTINCT could be expensive, so it seems less effective than Claude’s solution to me. I will give it 0.5 points.
--- Gemini's code
WITH first_and_last_orders AS (
SELECT
user_id,
order_id,
FIRST_VALUE(order_id) OVER (PARTITION BY user_id ORDER BY order_time) AS first_order_id,
LAST_VALUE(order_id) OVER (PARTITION BY user_id ORDER BY order_time) AS last_order_id
FROM orders
)
SELECT DISTINCT
user_id,
first_order_id AS order_id,
'first_order' AS order_label
FROM first_and_last_orders
UNION ALL
SELECT DISTINCT
user_id,
last_order_id AS order_id,
'last_order' AS order_label
FROM first_and_last_orders;
Round 3 Recap 🥁
In this query optimization round, Claude 3.5 Sonnet is the clear winner, getting all three questions correct with innovative solutions. ChatGPT-4o needed guidance on two questions but eventually answered all correctly, earning 2 points. Gemini Advanced had one syntax error and produced a less optimized code, resulting in 1.5 points.

Summary

🥇Claude 3.5 Sonnet (10 points)
- Claude performed the best in both SQL generation and optimization, failing only one question initially but quickly correcting it after clarification. I would 100% recommend Claude if you’re looking for an AI to assist with SQL queries.
- I also like their UI better as I can format text input for better readability.
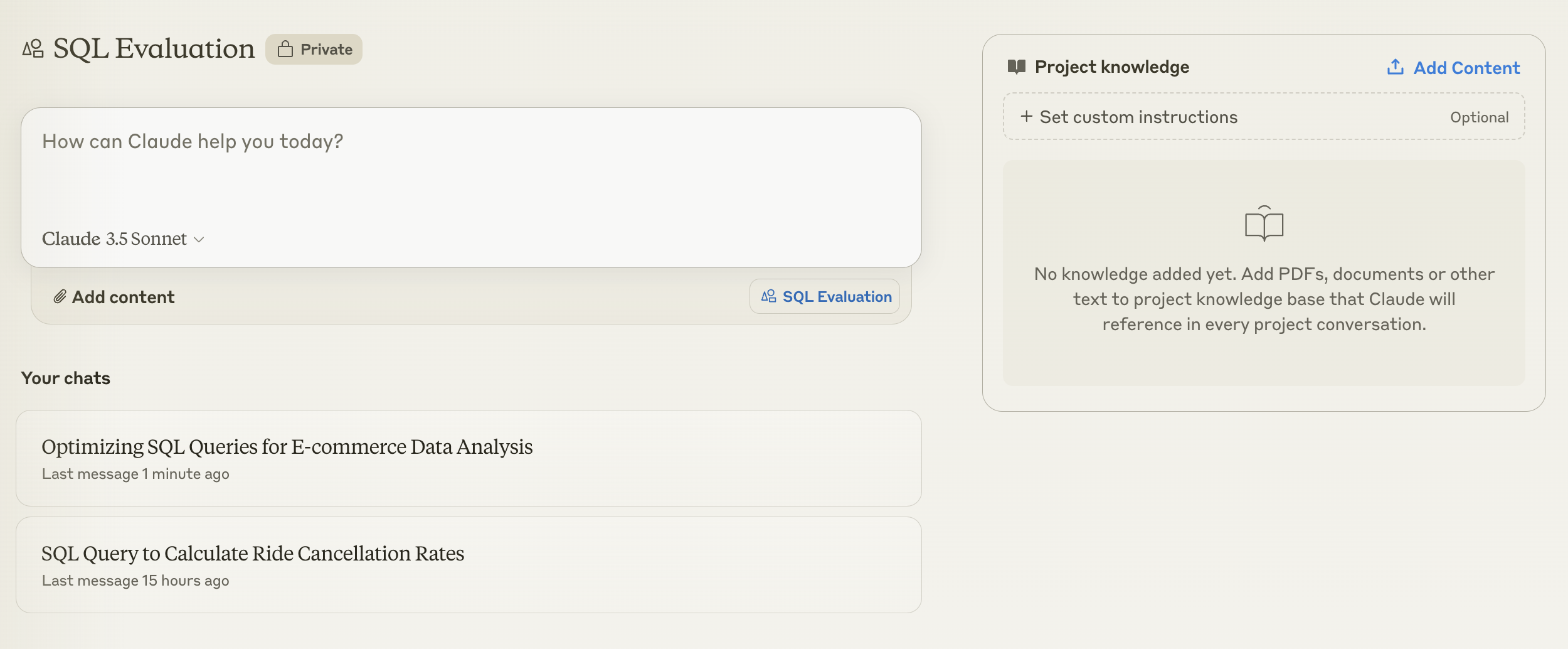
- Another feature I appreciate is their ‘project’ functionality - You can set custom instructions and share knowledge on the project level, making it handy for team use.
- However, its lower file upload limit could be a challenge if you want to share real datasets with it. The actual file size they accept seems to be way lower than what they claim and what ChatGPT allows, potentially due to the high demand. Hopefully, Claude will improve this feature soon.
🥈GPT-4o (8 points)
- GPT-4o is capable of writing syntactically correct SQL. It excels in business logic but lags in query optimization.
- A notable advantage of GPT-4o is the ability to load datasets and interact with them directly in the UI, aiding data understanding and exploration - you can read more about this feature in my article.
- Its ability to generate synthetic datasets with download links is also very impressive.
🥉Gemini Advanced (7 points)
- Gemini had worse performance in all three categories, compared to Claude and ChatGPT, but it still managed to get 70% of the questions correct.
- Being able to search the website and provide reference links could be its competitive advantage. However, based on my experiences above, the links sometimes were irrelevant or did not match its responses, undermining credibility.
- Another advantage of Gemini is it integrates with other Google Suite products. For example, you can open the datasets it generated in Google Spreadsheet.
What’s Next
Now that we have compared SQL skills, here are the other data science skills I plan to evaluate next. Please let me know if there are any additional areas you would like me to cover!
- Exploratory Data Analysis (EDA)
- Visualization
- Machine Learning
- Text Analytics
- Data Science Business Cases

