
FDLC Salary Data Visualization
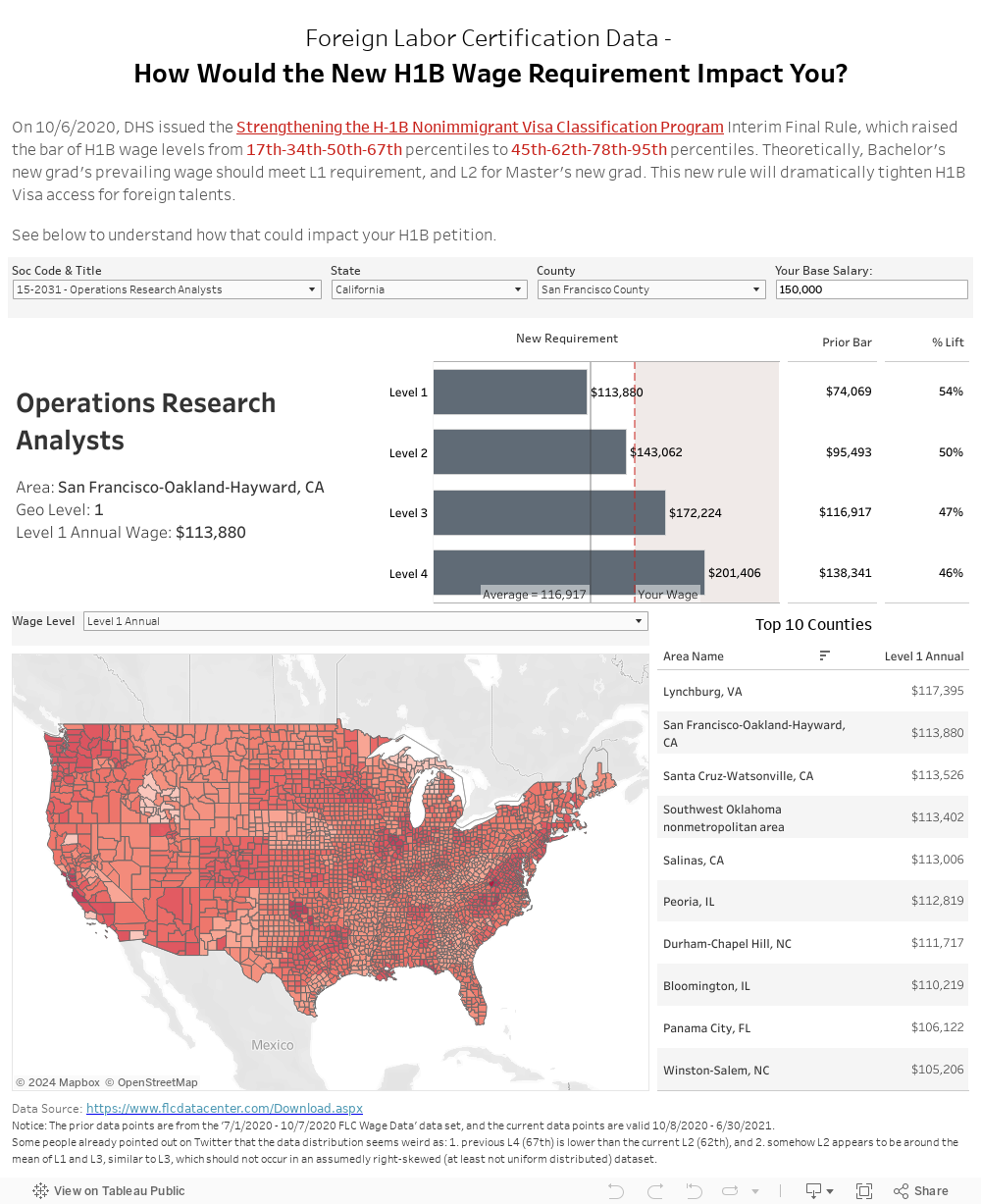
On 10/6/2020, DHS issued the Strengthening the H-1B Nonimmigrant Visa Classification Program Interim Final Rule, which raised the bar of the H1B wage levels from 17-34-50-67th percentiles to 45-62-78-95th percentiles. Theoretically, Bachelor’s new grad’s prevailing wage should meet L1 requirement, and L2 for Master’s new grad. This new rule will dramatically tighten H1B Visa access for foreign talents.
As an H1B visa holder, this news spread very fast among my friends who are in the same situation, with a lot of discussion of the potential impact and concern of the continuous policy uncertainty recently. To help understand how much it has raised the bar and how it could impact each one of us, I built a tableau dashboard based on the public wage level data from the FLC data center with the flexibility to query your own job code, location and base salary.
I also posted the dashboard on LinkedIn and in two weeks, the post got over 50k views in the feed, with over 500 reactions, and the dashboard also hit over 5k views. This definitely shows how much attention this issue has got, as well as how much we can do to the community with our own skillsets.
Dashboard
Please notice that all the visualizations are designed for desktop view, so it is recommended to view them on a desktop device.
Some Final Thoughts
- As a data analyst/scientist, we have to admit that all real-life datasets are messy, and this dataset is not an exception… For example, some job codes are coded with hourly wage, but some use annual wage; And many counties in the North East are not stored with their standard name thus lots of data cleaning and pre-processing is required. Missing values also exist in some counties and some job codes (e.g. 15-1132 in SF). Therefore, the best we can do is to admit their existence and try our best to make sense of them and present them in more readable and reasonable ways.
- Except the common and understandable data quality issues (inconsistent format, missing values, etc.), this dataset seems to have some more severe problems – As some people on twitter already pointed out, the data distribution looks very weird as 1. The previous L4 (67th) is lower than the current L2 (62nd) but the prior dataset was just published 3 months ago, and 2. somehow L2 appears to be around the mean of L1 and L3, similar to L3, which should not occur in an assumedly right-skewed (at least not uniform distributed) dataset. I hope the underlying data is reliable instead of people making new policies without much thoughts for the sake of politics…
- Many of us learned a lot of analytics, visualization, statistics, machine learning and all the other advanced data skills in school and work, but they can do more than just helping us find a job – we can use them to better understand the world and also make contribution to the community/society by extracting insights and presenting them in a more easy-to-understand way to more people.
Follow this link to find more weekly vizzes :)

