
Topic Summarization and Categorization with GPT
Context
Since 2021, I’ve dedicated Friday and Sunday nights to reading data science blogs, aiming for four to five each week. I summarize noteworthy articles on my blog bi-monthly (linked here). Recently, I’ve noticed an uptick in blogs related to LLM, sparking my curiosity about other trends in my reading habits. To analyze this, I realized I needed a categorized record of my past readings. Fortunately, GPT is here to assist!

Topic Extraction with GPT
ChatGPT excels in text analytics, efficiently summarizing and categorizing text. In the section below, I will walk through how I used the OpenAI API to call the gpt-3.5-turbo model for this task. While GPT-3.5 was chosen for cost reasons, it is proved sufficient for my purposes.
1. Dataset Preparation
Of course, the first step in any analysis is to prepare the dataset. Luckily, my reading summaries are consistently formatted, making this process smoother. I will skip the detailed data scraping process here since it is not the focus of this article, but the cleaned dataset comprises 521 rows (each representing a blog post I’ve read) and includes the following four columns:
- Id: Unique ID of the blog post (1 to 521)
- Month: When I read the blog post
- Title: Blog title
- Description: A one-sentence blog description

2. Topic Summarization
To understand shifting interests, I needed topic labels. So the second step I took was to ask GPT to summarize a list of topics from my reading list. I did this by simply concatenating all the blog titles and passing it to the OpenAI API. Please find the code snippet below.
import openai
openai.api_key = 'your_api_key'
## function to call ChatCompletion endpoint and return the responses
def get_completion(prompt, model="gpt-3.5-turbo"):
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0,
)
return response.choices[0].message["content"]
## concatenate blog titles into one long string
reading_notes["Id_Title"] = reading_notes['Id'].astype(str) + '. ' + reading_notes['Title']
titles = '; '.join(reading_notes['Id_Title'])
## GPT Prompt
prompt = f"""
I have a list of blog posts' names.
Please extract 15 common data science topics from it with one-sentence description of each topic.
The topics must be mutually exclusive as much as possible.
Here is the list. Post names are seperated by the semicolon:
'''
{titles}
'''
Output should look like this:
'''
1. Topic Extraction: How to identify and extract relevant topics from a large collection of text documents.
2. LLM Applications in Data Analysis: How to use LLM to run data analysis with natural language.
'''
"""
## call OpenAI API
response = get_completion(prompt)
Here are the 15 categories it generated. I would say the list makes a lot of sense and the descriptions are pretty accurate. However, you can still see some overlapping topics even though I asked it to be mutually exclusive. And it is missing some categories I am specifically interested in, for example, LLM. Therefore, I manually adjusted it accordingly.

3. Blog Categorization
With the topics and blog list ready, I categorized each blog using the OpenAI API and the below prompt.
## title_description below is a string of blog title and descirption from my data frame
prompt = f"""
Here is the name of a blog post and a short description:
'''
{title_description}
'''
Please categorize it under one of the topics below.
If a blog does not fit any of the categories below, please categorize it as 'Others'.
'''
1. A/B Testing and Causal Inference: Statistical approach to understand the cause-and-effect relationships using controlled experimentations and other causal inference techniques.
2. Text Mining: The process of extracting valuable information and insights from large volumes of unstructured textual data .
3. Customer Lifetime Value Prediction: Estimating the long-term value of a customer to a business.
4. Customer Segmentation: Applying techniques like clustering to group customers with similar demographics or product behaviros.
5. Recommender Systems: Algorithms that recommend items to users based on their preferences.
6. Time Series Analysis: Analyzing and forecasting trends in time-ordered data.
7. Anomaly Detection: Detecting outliers or unusual patterns in data.
8. Machine Learning Applications: Practical applications of machine learning algorithms in various industries.
9. Model Interpretation: Understanding and explaining the decision-making process and outputs of a machine learning model.
10. Data Quality Management: Ensuring the accuracy, completeness, and reliability of data.
11. Data Visualization: Creating visual representations of data to aid in analysis and decision-making.
12. Product Metrics: Key performance indicators used to measure the success of a product.
13. Data Science Career: Recent trend in the data science field and how to advance the data career.
14. Programming Tips: Suggestions to improve code efficiency in data science.
15. Large Language Model Applications: Applying Large Lanaguge Model to in various fields such as sentiment analysis and data analysis.
'''
The output MUST follow the json format as shown in the example below. The 'category' value MUST be one of the 15 categories above or 'Others'.
Example:
'''
INPUT: "**Data Quality Score: The Next Chapter of Data Quality at Airbnb**: Airbnb talks about the design of their newly invented 'data quality score' and its use cases"
OUTPUT: {"category":"Data Quality Management"}
'''
"""
We can iterate through the blog list and pass their title and descriptions to GPT one by one. However, one thing to note is that getting a consistent output format is usually critical to this type of task. In our case, we only need one output (category), so this is less of a problem. But just to showcase how we can enforce a consistent JSON format output, below I used the function calling capability and the response_format parameter from the OpenAI API.
## function defined for the OpenAI response format
func = [
{
"name": "get_blog_category",
"description": "Categorize blog posts",
"parameters": {
"type": "object",
"properties": {
"category": {
"type": "string",
"enum": [
"A/B Testing and Causal Inference",
"Text Mining",
"Customer Lifetime Value Prediction",
"Customer Segmentation",
"Recommender Systems",
"Time Series Analysis",
"Anomaly Detection",
"Machine Learning Applications",
"Model Interpretation",
"Data Quality Management",
"Data Visualization",
"Product Metrics",
"Data Science Career",
"Programming Tips",
"Large Language Model Applications",
"Others"
],
"description": "The category of the blog post",
},
},
"required": ["category"],
},
},
]
## updated function to get category output in JSON from OpenAI API
def get_category(title_description, model="gpt-3.5-turbo"):
example = """
INPUT: "**Data Quality Score: The Next Chapter of Data Quality at Airbnb**: Airbnb talks about the design of their newly invented 'data quality score' and its use cases"
OUTPUT: {"category":"Data Quality Management"}
"""
prompt = f"""
Here is name of a blog post and a short description:
'''
{title_description}
'''
Please categorize it under one of the topics below. If a blog does not fit any of the categories below, please categorize it as 'Others'.
'''
1. A/B Testing and Causal Inference: Statistical approach to understand the cause-and-effect relationships using controlled experimentations and other causal inference techniques.
2. Text Mining: The process of extracting valuable information and insights from large volumes of unstructured textual data .
3. Customer Lifetime Value Prediction: Estimating the long-term value of a customer to a business.
4. Customer Segmentation: Applying techniques like clustering to group customers with similar demographics or product behaviros.
5. Recommender Systems: Algorithms that recommend items to users based on their preferences.
6. Time Series Analysis: Analyzing and forecasting trends in time-ordered data.
7. Anomaly Detection: Detecting outliers or unusual patterns in data.
8. Machine Learning Applications: Practical applications of machine learning algorithms in various industries.
9. Model Interpretation: Understanding and explaining the decision-making process and outputs of a machine learning model.
10. Data Quality Management: Ensuring the accuracy, completeness, and reliability of data.
11. Data Visualization: Creating visual representations of data to aid in analysis and decision-making.
12. Product Metrics: Key performance indicators used to measure the success of a product.
13. Data Science Career: Recent trend in the data science field and how to advance the data career.
14. Programming Tips: Suggestions to improve code efficiency in data science.
15. Large Language Model Applications: Applying Large Lanaguge Model to in various fields such as sentiment analysis and data analysis.
'''
The output MUST follow the json format as shown in the example below. The 'category' value MUST be one of the 15 categories above or 'Others'.
Example:
'''
{example}
'''
"""
## you should handle exceptions and add retry logic below
## but for simplicity, showing the bare minimum here
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0,
tools=[{"type":"function", "function":func[0]}], ### enable function calling
response_format={"type":"json_object"} ### force json output
)
func_response = response["choices"][0]["message"]["tool_calls"][0]["function"]
func_arguments = json.loads(func_response["arguments"])
category = func_arguments["category"]
return category
The categorization was done pretty fast (<15mins for 500+ blogs) even though I was just calling them one by one. I manually validated the output and was satisfied with the accuracy. However, I do see it coming up with 3 categories that do not fall under the 15 I provided or ‘Others’. This is commonly seen in my other exercises since GPT is not rule-based – you provide it rules but it can decide not to follow :) But the occurrence here (3/521) is acceptable and I just manually adjusted the three.
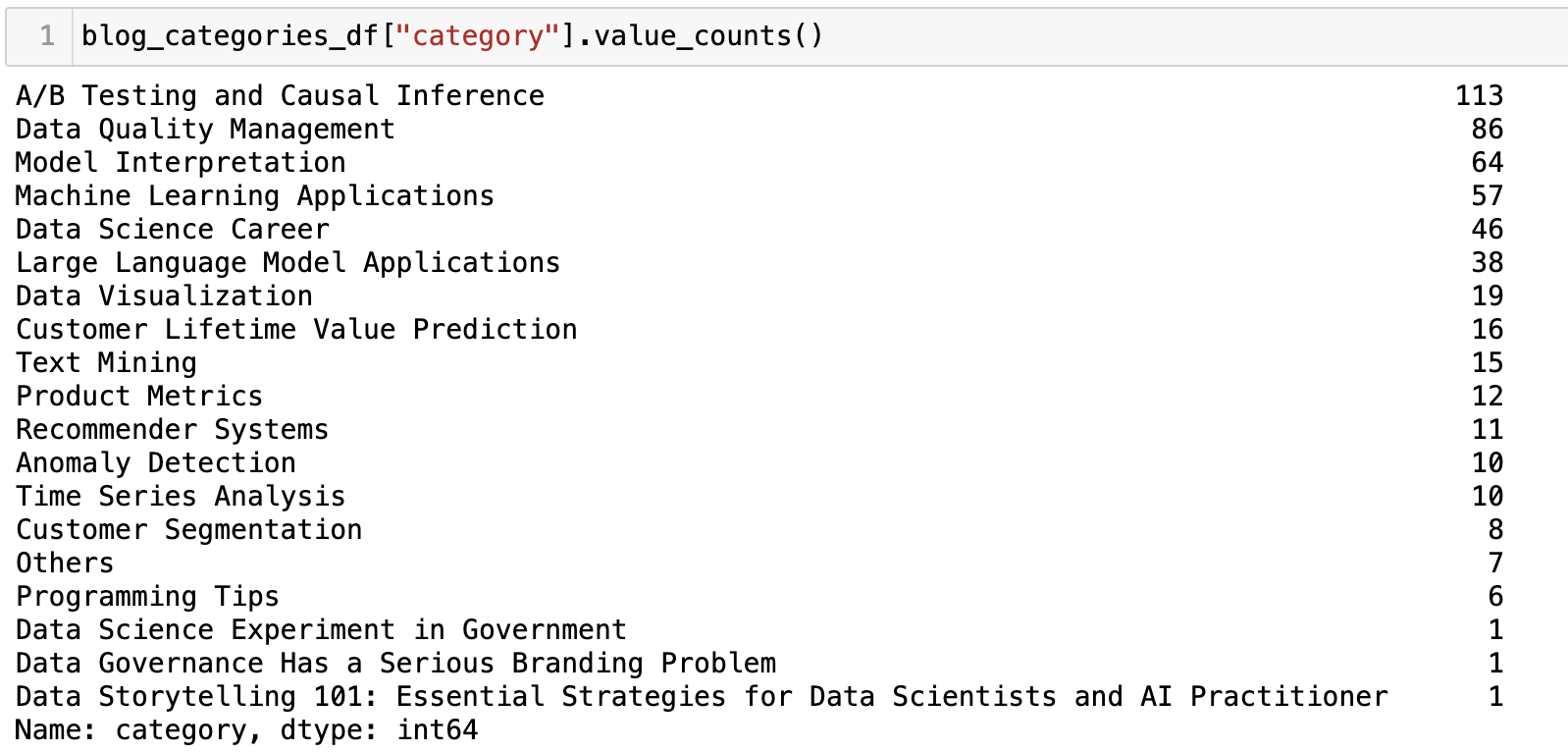
4. Data Analysis
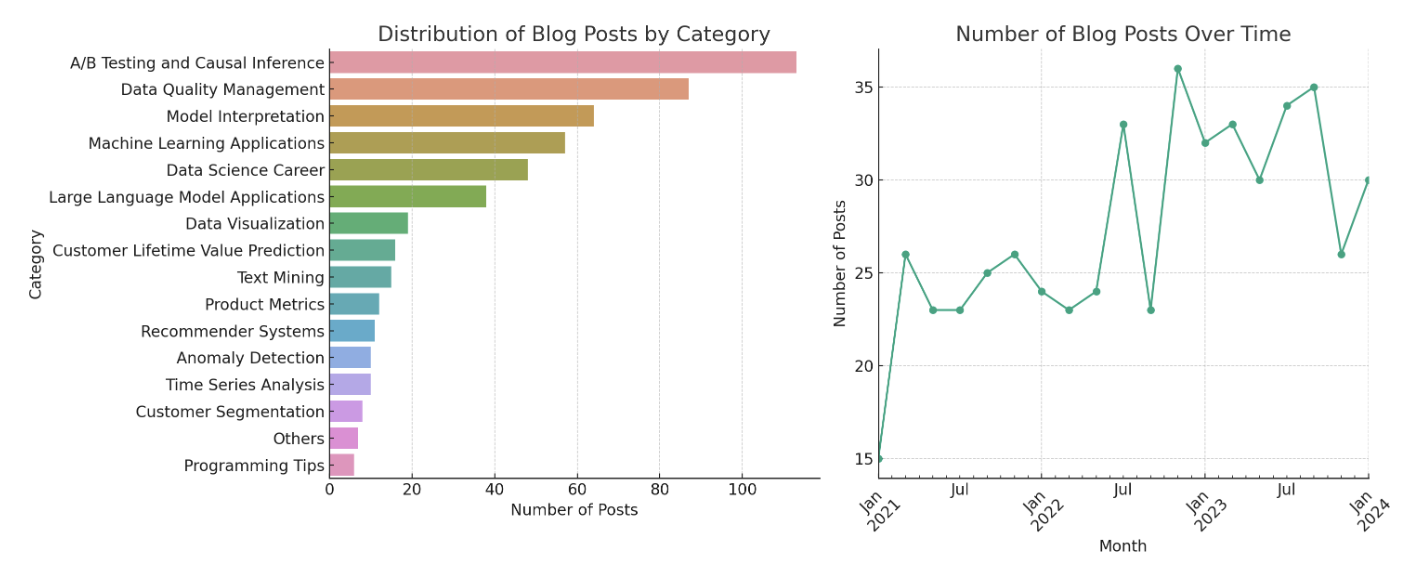
After merging the category predictions with our initial dataset, now it’s time for some analysis! I simply uploaded the dataset to the ChatGPT UI and asked it to analyze the dataset. It made some quick visualization from it, showing the categories’ frequencies and the # of blogs read over time. It is clear that A/B Testing and Causal Inference has been my favorite topic in the past three years, followed by Data Quality Management. And the number of blogs I read has increased significantly in 2023.
It also made a word cloud based on word frequency – no surprise data is at the center.
However, this didn’t fully answer how my interests evolved over time. I followed up with GPT, who then generated this heatmap. Despite multiple attempts, it failed to extract insights from it effectively.
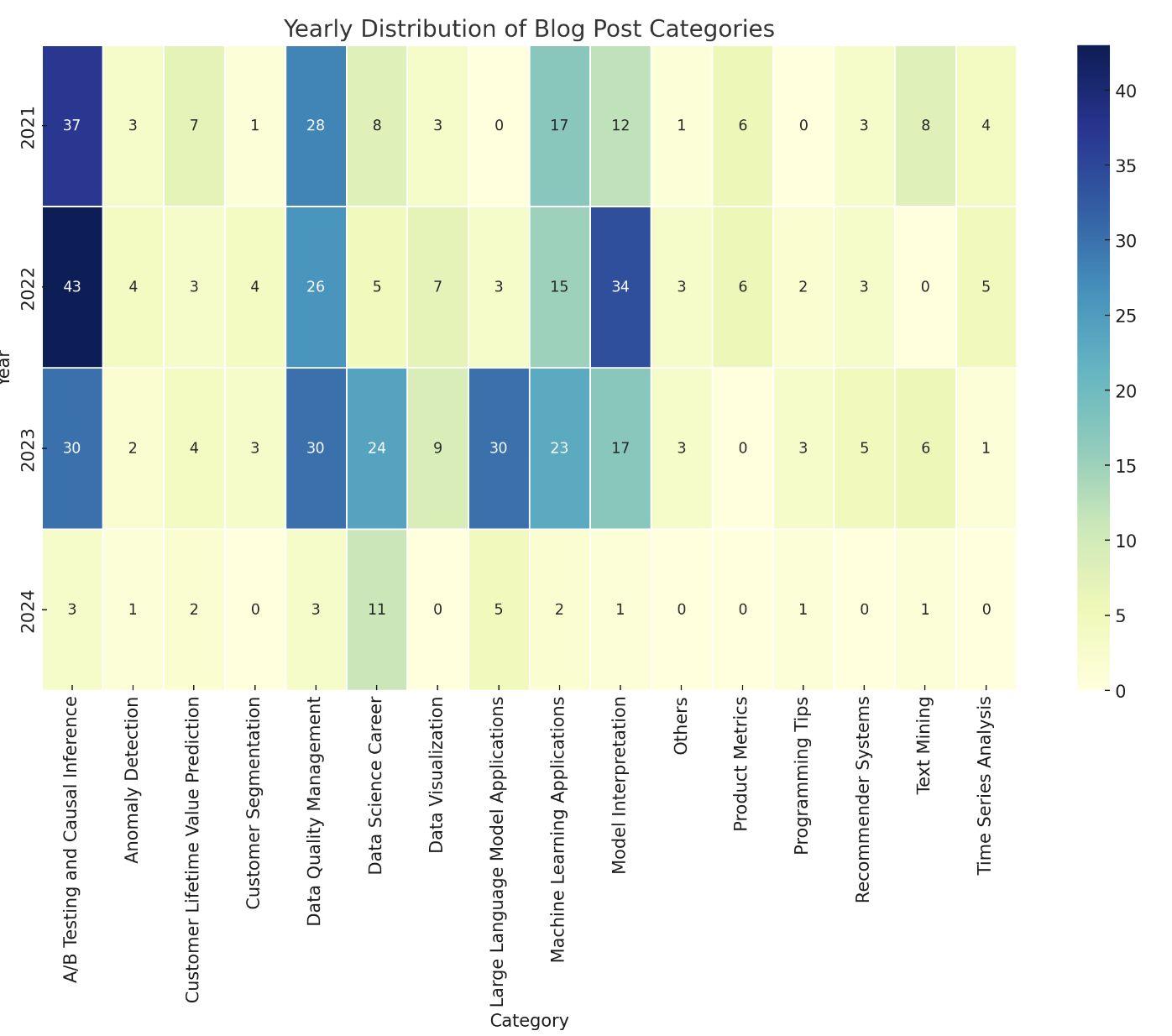
So let me answer my question myself:
- A/B Testing and Causal Inference consistently intrigued me. It is a complicated area with lots of interesting methodologies. Besides, since I have read lots of them, Medium keeps showing more on my homepage – that’s how the recommender system works :)
- Data Quality Management surprisingly emerged as a major interest all time – I honestly didn’t expect this high volume but I guess I was just troubled too much by data management at work.
- The Machine Learning Applications category is broad and thus also remains prominent.
- In 2023, two categories popped up compared to the previous years – Data Science Career and LLM Applications. This matches my expectations well. LLM of course is a hot area that I am learning and trying to keep up with. And I have also been thinking more and more about my career growth with longer industry experience and all the layoffs I have seen in the DS field in the past year.
More Use Cases
The above case demonstrated how to use OpenAI API to conduct high-quality text summarization and categorization. This is of course a toy example, but it has great potential in the industry.
At Brex, one project I have been leading is to build an AI-powered engine to identify customer insights. We built a data pipeline that employs a similar approach to conduct automated summarization, categorization, and sentiment analysis on customer feedback we collected from 20+ data sources. Collaborating with engineers, this has evolved into a one-stop shop for all internal users to quickly identify customer pain points related to their product domains. We have detailed this further in a Brex tech blog and are exploring more applications, such as utilizing embeddings to conduct semantic searches in the large volume of customer feedback.
GPT has revolutionized topic modeling and text analysis, making it more accessible and user-friendly compared to previous methods. We tried BERT before for the same task (classifying customer feedback), but it was more labor-intensive and not necessarily more effective. This is why I wrote this blog to share real-world examples, and hopefully, this will inspire your own ventures in this field!
